
Hive简介
在介绍Hive的框架和执行流程之前,这里首先对Hive进行简要的介绍。
Hive 是建立在 Hadoop 上的数据仓库基础构架。它提供了一系列的工具,可以用来进行数据抽取,转化,加载(ETL),这是一种可以存储、查询和分析存储在 Hadoop 中的大规模数据的机制。Hive 定义了简单的类 SQL 查询语言,称为Hive QL,它允许熟悉 SQL 的用户查询数据。同时,这个语言也允许熟悉 MapReduce 开发者的开发自定义的 mapper 和 reducer 来处理内建的 mapper 和 reducer 无法完成的复杂的分析工作。
这里假设已经对Hive的各个组成部分、作用以及Hive QL语言有了基本的认识,不再做详细的解释,更加关注的是Hive源码级别的解析。下面是从网络上摘取的两个关于Hive框架的解析图:
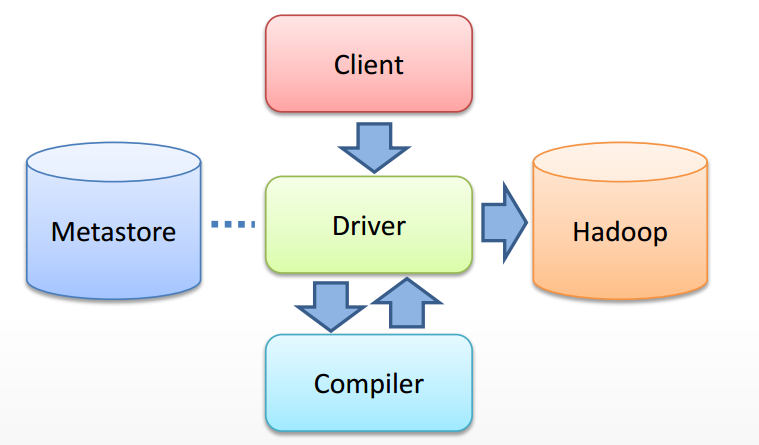
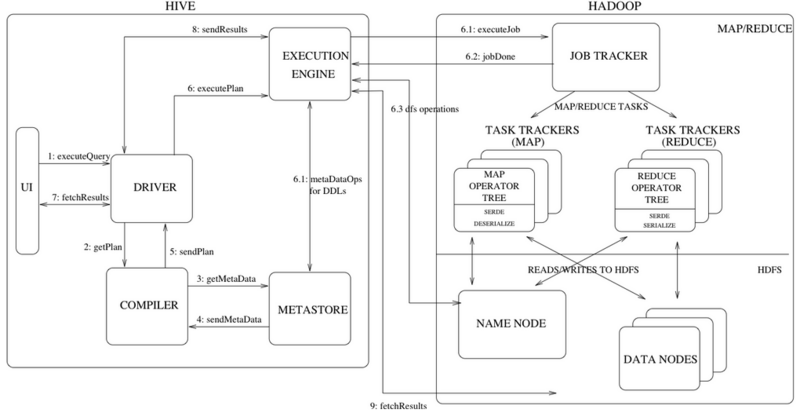
从框架图中我们可以看见从用户提交一个查询(假设通过CLI入口)直到获取最终结果,Hive内部的执行流程主要包括:
- CLI 获取用户查询,解析用户输入的命令,提交给Driver;
- Driver 结合编译器(COMPILER)和元数据库(METASTORE),对用户查询进行编译解析;
- 根据解析结果(查询计划)生成MR任务提交给Hadoop执行;
- 获取最终结果;
源码分析
我们试图根据Hive的源码对上述过程的每一步进行解析, 使用的源码版本1.1.0。话不多说,首先看看CLI如何解析用户的输入,并提交给Driver类执行的。这个过程主要涉及的类是org\apache\hadoop\hive\cli\CliDriver.java。
main入口
执行入口,main函数,创建CliDriver实例,接受用户输入参数,开始运行。
1 | public static void main(String[] args) throws Exception { |
这里用到了创建CliDriver实例,看看CliDriver的构造函数内部都做了什么操作:
1 | public CliDriver() { |
首先获取一个SessionState, SessionState封装了一个会话的关联的数据,包括配置信息HiveConf,输入输出流,指令类型,用户名称、IP地址等等。SessionState 是一个与线程关联的静态本地变量ThreadLocal,任何一个线程都对应一个SessionState,能够在Hive代码的任何地方获取到(大量被使用到),以返回用户相关或者配置信息等。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22private static ThreadLocal<SessionState> tss = new ThreadLocal<SessionState>();
public static SessionState get() {
return tss.get();
}
public static SessionState start(HiveConf conf) {
//创建一个SessionState
SessionState ss = new SessionState(conf);
return start(ss);
}
public static SessionState start(SessionState startSs) {
setCurrentSessionState(startSs);
.....
}
public static void setCurrentSessionState(SessionState startSs) {
//将SessionState与线程本地变量tss关联
tss.set(startSs);
Thread.currentThread().setContextClassLoader(startSs.getConf().getClassLoader());
}
接着CliDriver的构造函数来说,获取到SessionState之后,就初始化配置信息org.apache.hadoop.conf.Configuration conf.
run
CliDriver实例创建完毕,调用run(args), 开始处理用户输入。run方法的函数体比较长,为了方便阅读,下面按照代码的出现顺序,依次解析。
step 1. 对输入的指令进行初步解析,提取-e -h hiveconf hivevar等参数信息,设置用户提供的系统和Hive环境变量。详细实现,参考OptionsProcessor类,不再详细描述。
1 | OptionsProcessor oproc = new OptionsProcessor(); |
step 2. 初始化Log4j日志组件
1 | boolean logInitFailed = false; |
step 3. 初始化HiveConf,并根据HiveConf实例化CliSessionState,设置输入输出流为标准控制台。
CliSessionState 继承了SessionState类,创建了一些记录用户输入的字符串,在实例化的过程中,主要是用来记录HiveConf,并生成一个会话ID,参见SessionState构造函数.
1 | CliSessionState ss = new CliSessionState(new HiveConf(SessionState.class)); |
step 4. 根据stage1解析的参数内容,填充CliSessionState的字符串,比如用户输入了-e 则这个stage就把-e 对应的字符串赋值给CliSessionState的 execString成员。
1 | if (!oproc.process_stage2(ss)) { |
step 5. 在允许打印输出的模式下,如果日志初始化失败,打印失败信息
1 | if (!ss.getIsSilent()) { |
step 6. 将用户命令行输入的配置信息和变量等,覆盖HiveConf的默认值
1 | HiveConf conf = ss.getConf(); |
step 7. 设置当前回话状态,执行CLI驱动
1 | SessionState.start(ss); |
executeDriver
在进入executeDriver之前,我们可以认为Hive处理的是用户进入Hive程序的指令,到此用户已经进入了Hive,Cli的Driver将不断读取用户的HiveQL语句并解析,提交给Driver。executeDriver函数内部出了根据用户参数做出的一些执行响应外,还设置了用户HiveQL的执行历史记录,也就是方便我们使用上下标键查看之前执行的指令的功能,不再详述。executeDriver函数内部核心的代码是通过while循环不断按行读取用户的输入,然后调用ProcessLine拼接一条命令cmd,传递给processCmd处理用户输入。下面就来看看processCmd函数。
processCmd
- 首先是设置当前clisession的用户上一条指令,然后使用正则表达式,将用户输入的指令从空格,制表符等出断开(tokenizeCmd函数),得到token数组。
1 | CliSessionState ss = (CliSessionState) SessionState.get(); |
然后根据用户的输入,进行不同的处理,这边的处理主要包括:
- quit或exit: 关闭回话,退出hive
- source: 文件处理?不清楚对应什么操作
!开头: 调用Linux系统的shell执行指令- 本地模式:创建CommandProcessor, 执行用户指令
限于篇幅原因,前面三种情况的代码不再详述,重点介绍Hive的本地模式执行,也就是我们常用的HiveQL语句,DFS命令等的处理方式:
1 | try { |
其中,CommandProcessor是一个接口类,定义如下:1
2
3
4public interface CommandProcessor {
void init();
CommandProcessorResponse run(String command) throws CommandNeedRetryException;
}
CommandProcessorFactory根据用户指令生成的tokens和配置文件,返回CommandProcessor的一个具体实现。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21public static CommandProcessor get(String[] cmd, HiveConf conf)
throws SQLException {
CommandProcessor result = getForHiveCommand(cmd, conf);
if (result != null) {
return result;
}
if (isBlank(cmd[0])) {
return null;
} else {
if (conf == null) {
return new Driver();
}
Driver drv = mapDrivers.get(conf);
if (drv == null) {
drv = new Driver();
mapDrivers.put(conf, drv);
}
drv.init();
return drv;
}
}
其中getForHiveCommand函数首先根据tokens的第一个字串,也就是用户输入指令的第一个单词,在HiveCommand这个enum中定义的一些非SQL查询操作集合中进行匹配,确定相应的HiveCommand类型。在依据HiveCommand选择合适的CommandProcessor实现方式,比如dfs命令对应的DFSProcessor,set命令对应的SetProcessor等,如果用户输入的是诸如select之类的SQL查询, getForHiveCommand返回null,直接在get函数中根据配置文件conf选择或者生成一个Driver类实例,并作为CommandProcessor返回。详细的代码参考CommandProcessorFactory和HiveCommand类。
processLocalCmd
到此Hive对用户的一个指令cmd,配置了回话状态CliSessionState,选择了一个合适的CommandProcessor, CliDriver将进行他的最后一步操作,提交用户的查询到指定的CommandProcessor,并获取结果。这一切都是在processLocalCmd中执行的。
processLocalCmd函数的主体是一个如下的循环:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88do {
try {
needRetry = false;
if (proc != null) {
//如果CommandProcessor是Driver实例
if (proc instanceof Driver) {
Driver qp = (Driver) proc;
//获取标准输出流,打印结果信息
PrintStream out = ss.out;
long start = System.currentTimeMillis();
if (ss.getIsVerbose()) {
out.println(cmd);
}
qp.setTryCount(tryCount);
//driver实例运行用户指令,获取运行结果响应码
ret = qp.run(cmd).getResponseCode();
if (ret != 0) {
qp.close();
return ret;
}
// 统计指令的运行时间
long end = System.currentTimeMillis();
double timeTaken = (end - start) / 1000.0;
ArrayList<String> res = new ArrayList<String>();
//打印查询结果的列名称
printHeader(qp, out);
// 打印查询结果
int counter = 0;
try {
if (out instanceof FetchConverter) {
((FetchConverter)out).fetchStarted();
}
while (qp.getResults(res)) {
for (String r : res) {
out.println(r);
}
counter += res.size();
res.clear();
if (out.checkError()) {
break;
}
}
} catch (IOException e) {
console.printError("Failed with exception " + e.getClass().getName() + ":"
+ e.getMessage(), "\n"
+ org.apache.hadoop.util.StringUtils.stringifyException(e));
ret = 1;
}
//关闭结果
int cret = qp.close();
if (ret == 0) {
ret = cret;
}
if (out instanceof FetchConverter) {
((FetchConverter)out).fetchFinished();
}
console.printInfo("Time taken: " + timeTaken + " seconds" +
(counter == 0 ? "" : ", Fetched: " + counter + " row(s)"));
} else {
//如果proc不是Driver,也就是用户执行的是非SQL查询操作,直接执行语句,不自信FetchResult的操作
String firstToken = tokenizeCmd(cmd.trim())[0];
String cmd_1 = getFirstCmd(cmd.trim(), firstToken.length());
if (ss.getIsVerbose()) {
ss.out.println(firstToken + " " + cmd_1);
}
CommandProcessorResponse res = proc.run(cmd_1);
if (res.getResponseCode() != 0) {
ss.out.println("Query returned non-zero code: " + res.getResponseCode() +
", cause: " + res.getErrorMessage());
}
ret = res.getResponseCode();
}
}
} catch (CommandNeedRetryException e) {
//如果执行过程中出现异常,修改needRetry标志,下次循环是retry。
console.printInfo("Retry query with a different approach...");
tryCount++;
needRetry = true;
}
} while (needRetry);
前面对函数中关键的执行语句已经给出了注释,这里单独对printHeader进行一下说明。printHeader函数通过调用driver.getSchema.getFiledSchema,获取查询结果的列集合 ,然后依次打印出列名。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16private void printHeader(Driver qp, PrintStream out) {
List<FieldSchema> fieldSchemas = qp.getSchema().getFieldSchemas();
if (HiveConf.getBoolVar(conf, HiveConf.ConfVars.HIVE_CLI_PRINT_HEADER)
&& fieldSchemas != null) {
// Print the column names
boolean first_col = true;
for (FieldSchema fs : fieldSchemas) {
if (!first_col) {
out.print('\t');
}
out.print(fs.getName());
first_col = false;
}
out.println();
}
}