
笔者亲身经历的一次线上服务雪崩,可谓刻骨铭心…经过此次故障,不断反思,不断复盘,成长颇多。
背景
10.15 下午16:55开始,UPM - API 服务接口延时&报错数报警猛增(错误数多为500,502,499,504),一度UPM-API无法对外提供服务。通过排查定位到接口/user/get/permissions调用量增加了十倍(20QPS),因此给/user/get/permissions接口加了限流策略,18:17 UPM-API故障解除。
故障点错误数监控: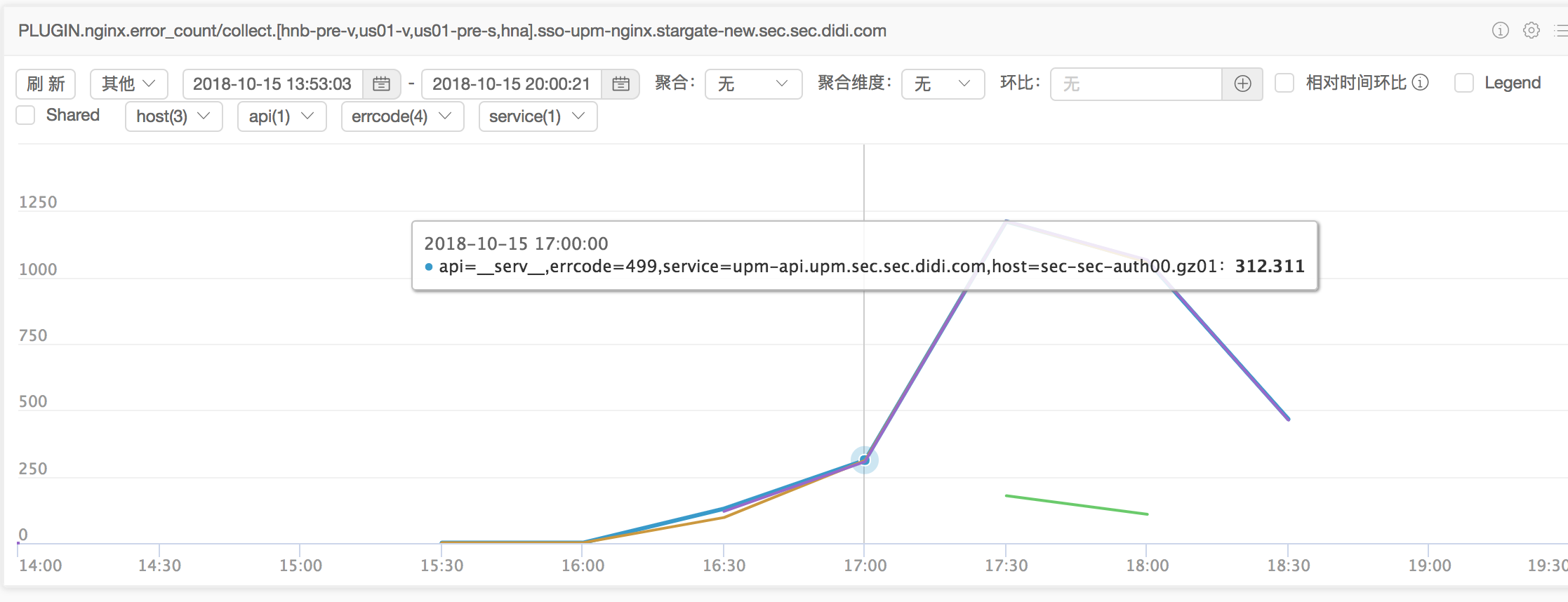
可以看出故障点499错误数(还有500,502)猛增。499错误码一般发生在客户端主动断开连接,当服务端处理慢了,超过了客户端的超时时间,就会抛出499。
故障点99分位接口延时监控: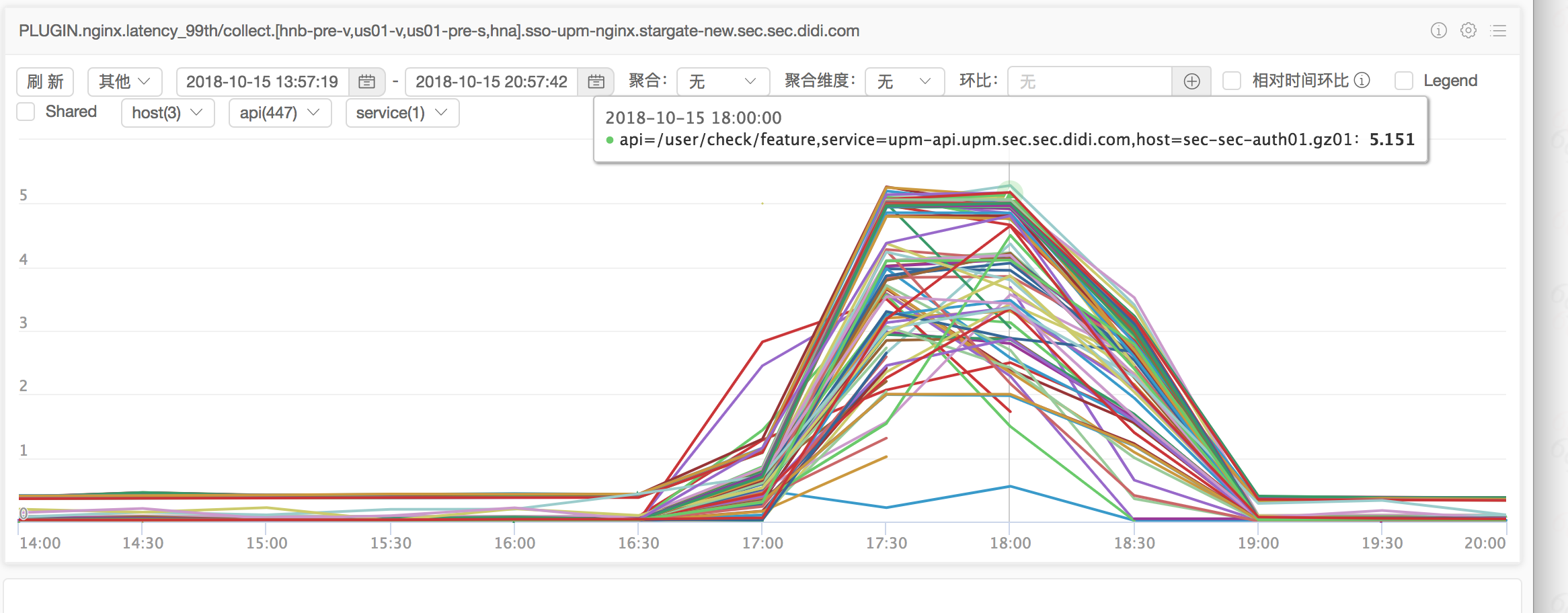
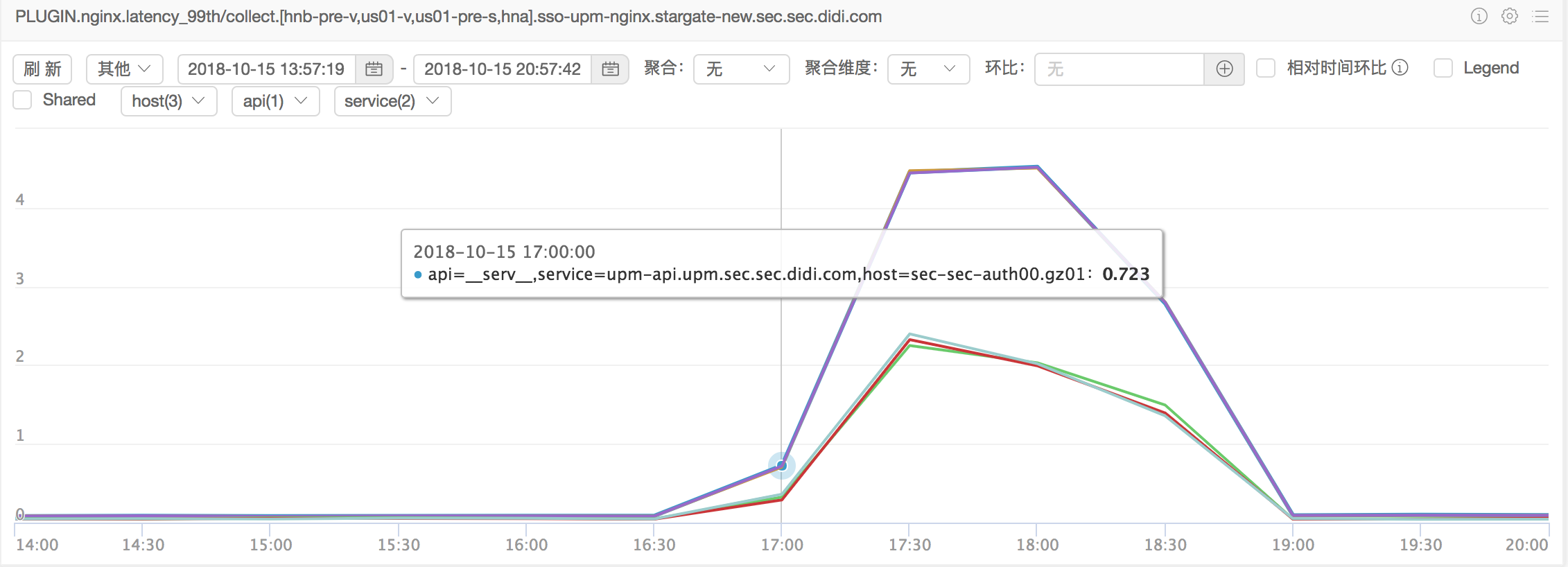
可以发现故障点接口服务几乎整体都受到了影响,接口延迟最差的时候到了5s左右。
故障点CPU Idle:
17:00左右出故障的时候进一步下跌。因此排查思路是“什么导致了CPU IDLE异常下跌。”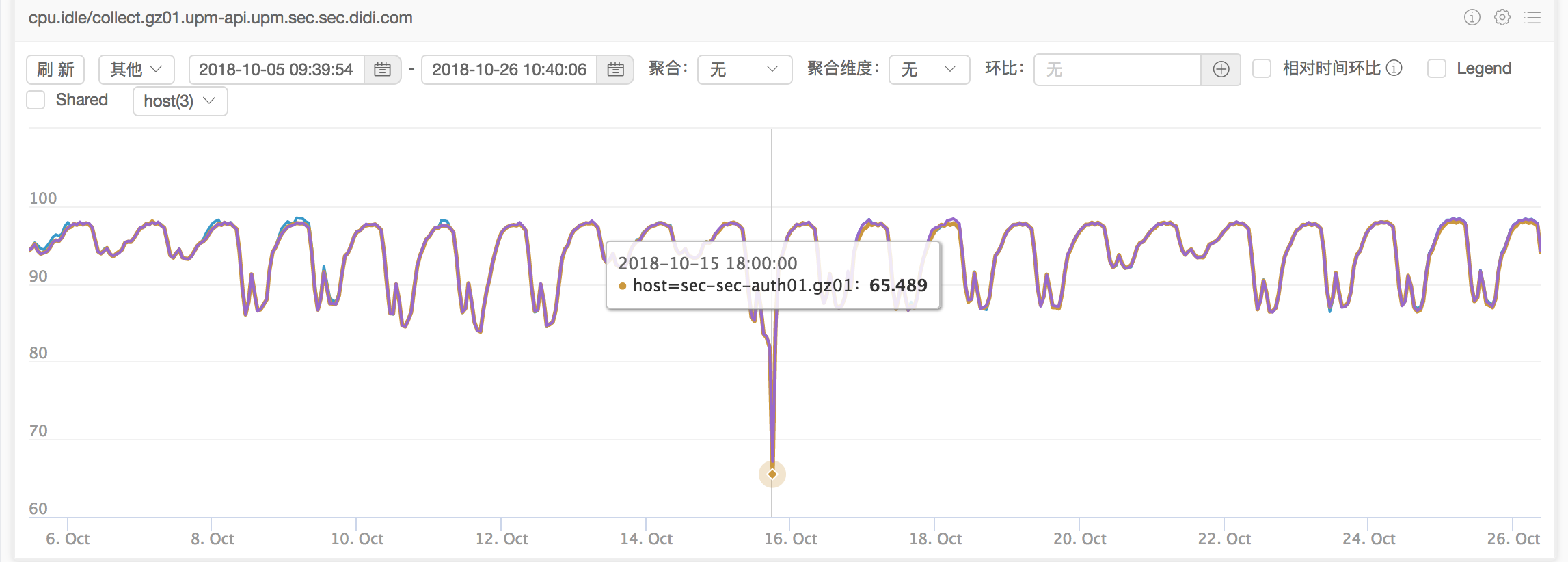
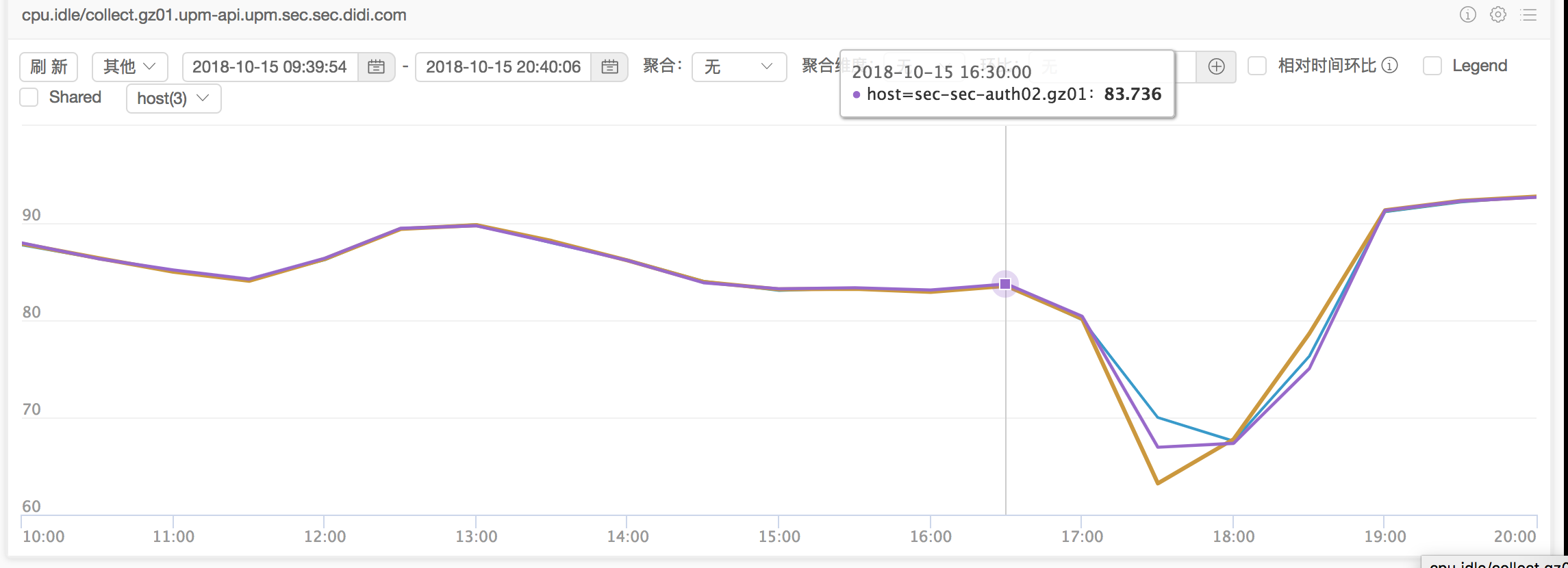
通过看20天的CPU波动图,可以看出故障点附近CPU IDLE异常下跌(机器3*48core 物理机)。看故障点CPU IDLE,可以看出16:30 CPU IDLE 83.736%,
/user/get/permissions QPS情况: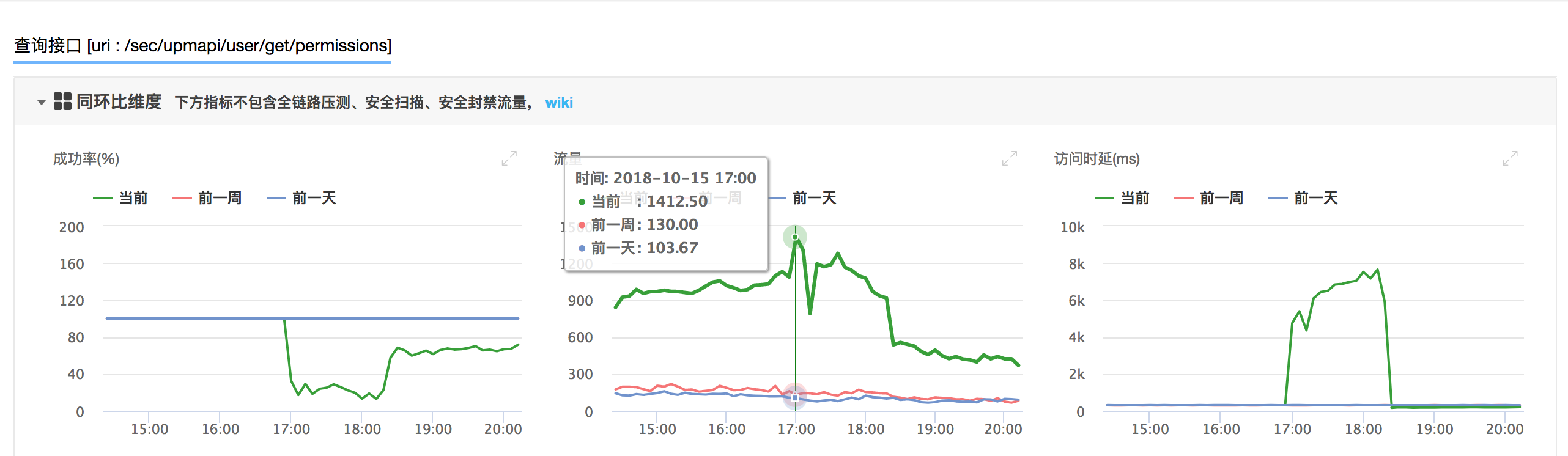
再看/user/get/permissions流量在17点左右流量较上周/前一天均增加了百倍。QPS达到23(1412/60s)左右系统难以支持,引发UPM API所有服务雪崩。
/user/get/permissions 问题复现
问题复现的最好办法是就是找没有正式流量的机器进行压测,由于我们YS机房刚好没有正式线上流量,并且已经部署完毕(4 core / 8Gi /10台docker soa-serivce服务)。于是选择对YS机房进行压测。
不过为了使压测准确,需要先看下引发故障的这个接口的代码逻辑,模拟出尽量真实的压测接口参数
代码逻辑:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74@GetMapping("/get/permissions")
public ResponseEntity<PermisssionResponseDto> getPermissions(@SessionAttribute(ApiConstants.REQUEST_APPID) Long appId,
UserParamDto userParamDto) {
--- 隐去不重要代码 ---
UserDto userDto = getUserByName(userParamDto);
PermisssionResponseDto response = new PermisssionResponseDto();
response.setUser(BeanUtils.map(UserResponseDto.class, userDto));
// 获取用户的所有角色 - 有缓存
List<RoleDto> roleDtoList = userService.selectRoleByUserId(appId, userDto.getId());
response.setRoles(BeanUtils.mapList(RoleResponseDto.class, roleDtoList));
List<Long> roleIds = new ArrayList<>();
if (roleDtoList != null) {
roleIds = roleDtoList.stream().map(RoleDto::getId).collect(Collectors.toList());
}
// 获取用户的flag - 查DB,无缓存,但是有索引
List<FlagDto> flagList = userService.selectFlagByUserId(appId, userDto.getId(), roleIds);
response.setFlags(BeanUtils.mapList(FlagResponseDto.class, flagList));
// 获取用户地区 - 猜测是他引起的故障
List<AreaDto> appUserAreaDto = appUserAreaService.selectUserAreaBusinessList(userDto.getId(), appId,
null, true, false);
response.setAreas(BeanUtils.mapList(AreaResponseDto.class, appUserAreaDto));
return ResponseEntity.success(response);
}
public List<AreaDto> selectUserAreaBusinessList(Long userId, Long appId, List<Long> businessIds, boolean needChild,
boolean childTypeIsParent) {
// 获取用户绑定的地区
List<AppUserArea> appUserAreaList = appUserAreaMapper.selectUserAreaBusinessList(userId, appId, businessIds, null);
// 获取businessIds绑定的地区 - businessId =null导致返回了全表数据
Map<Long, AppUserArea> appUserAreaMap = appUserAreaList.stream()
.collect(Collectors.toMap(o -> o.getAreaId(), v -> v, (o1, o2) -> o2));
appUserAreaList.addAll(getRoleArea(appId, userId, appUserAreaMap, businessIds));
Wrapper<Area> areaWrapper = new EntityWrapper<>();
// 致命所在!businessIds传递的是null, mybatis-plus in的输入参数为null时候默认为全部
areaWrapper.in("business_id", businessIds);
areaWrapper.eq("is_delete", IsDeleteEnums.NODELETE.getValue());
List<Area> areaList = areaMapper.selectList(areaWrapper);
List<Area> res;
if (childTypeIsParent) {
res = mergeChildWithParentId(appUserAreaList, areaList, needChild);
} else {
res = mergeChildWithLeftRight(appUserAreaList, areaList, needChild);
}
return BeanUtils.mapList(AreaDto.class, res);
}
private List<Area> mergeChildWithLeftRight(List<AppUserArea> appUserAreaList, List<Area> areaList,
boolean needChild) {
Map<Long, Area> areaMap = areaList.stream().collect(Collectors.toMap(Area::getId, s -> s, (e, n) -> e));
List<Area> response = new ArrayList<>();
// 二重循环计算量巨大
for (AppUserArea au : appUserAreaList) {
Area area = areaMap.get(au.getAreaId());
response.add(area);
if (needChild) {
for (Area a : areaList) {
if (a.getLft() > area.getLft() && a.getRght() < area.getRght() && a.getBusinessId()
.equals(area.getBusinessId())) {
response.add(a);
}
}
}
}
return response;
}
通过看selectUserAreaBusinessList代码可以猜出问题所在:MyBatis-Plus是 Mybatis 的增强工具, 可以方便做数据层的开发操作。但是 areaWrapper.in(“business_id”, businessIds); 一旦businessIds为null的时候,操作为搜索全表所有数据。因此其算法复杂度为最差O(n*m),平均O(n),最好O(n),其中n为upm_area表的未被删除的记录数(目前38000+,并且还会持续增大),m为用户绑定的地区数。返回全表地区数据创建的这个List areaList对象消耗性能实在是太大了,会占用大量的连接以及JVM内存。
《深入理解Java虚拟机》中曾指出,占据大量连续内存空间的大对象(典型的大对象就是那种很长的字符串以及数组),对虚拟机的内存分配来说,是一件坏消息,特别是一群“朝生夕灭”的“短命大对象”,容易引发Full GC。所以猜测,流量高起来的时候,List的频繁分配容易触发高频的FGC,进而导致服务雪崩。
单接口压测验证
通过单接口压测,发现当QPS=60的时候,CPU掉底为0。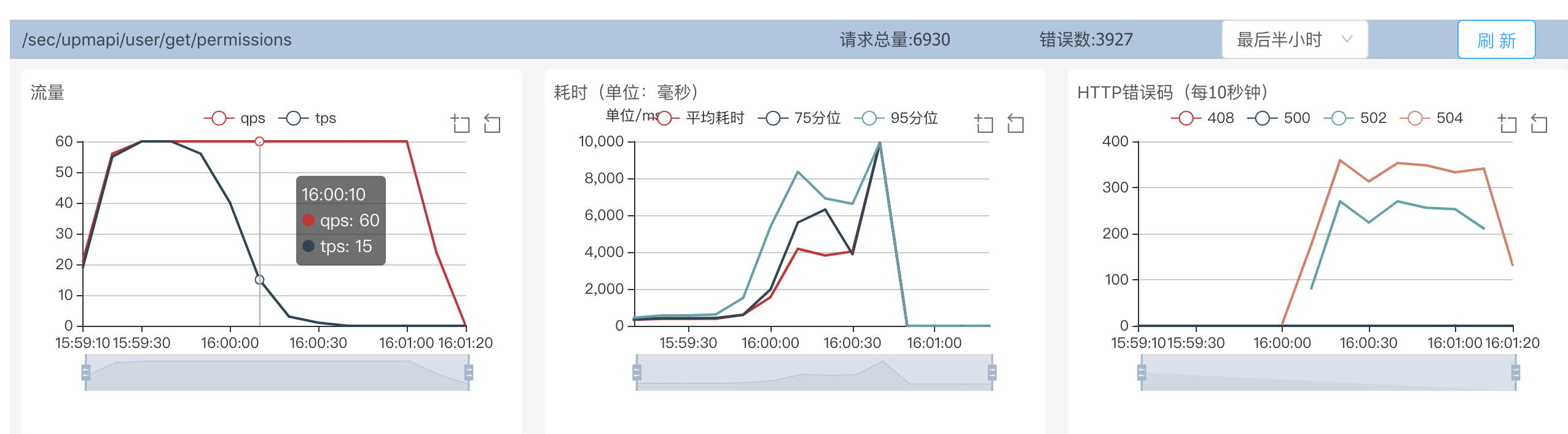
通过top查看消耗CPU的进程pid为1557, 使用JVM 的jstack工具打印 1557进程的所有线程当前时刻正在执行的方法堆栈追踪情况,即线程快照。通过快照可以定位出线程长时间出现停顿的原因。
jstack 1557 > 1557.log
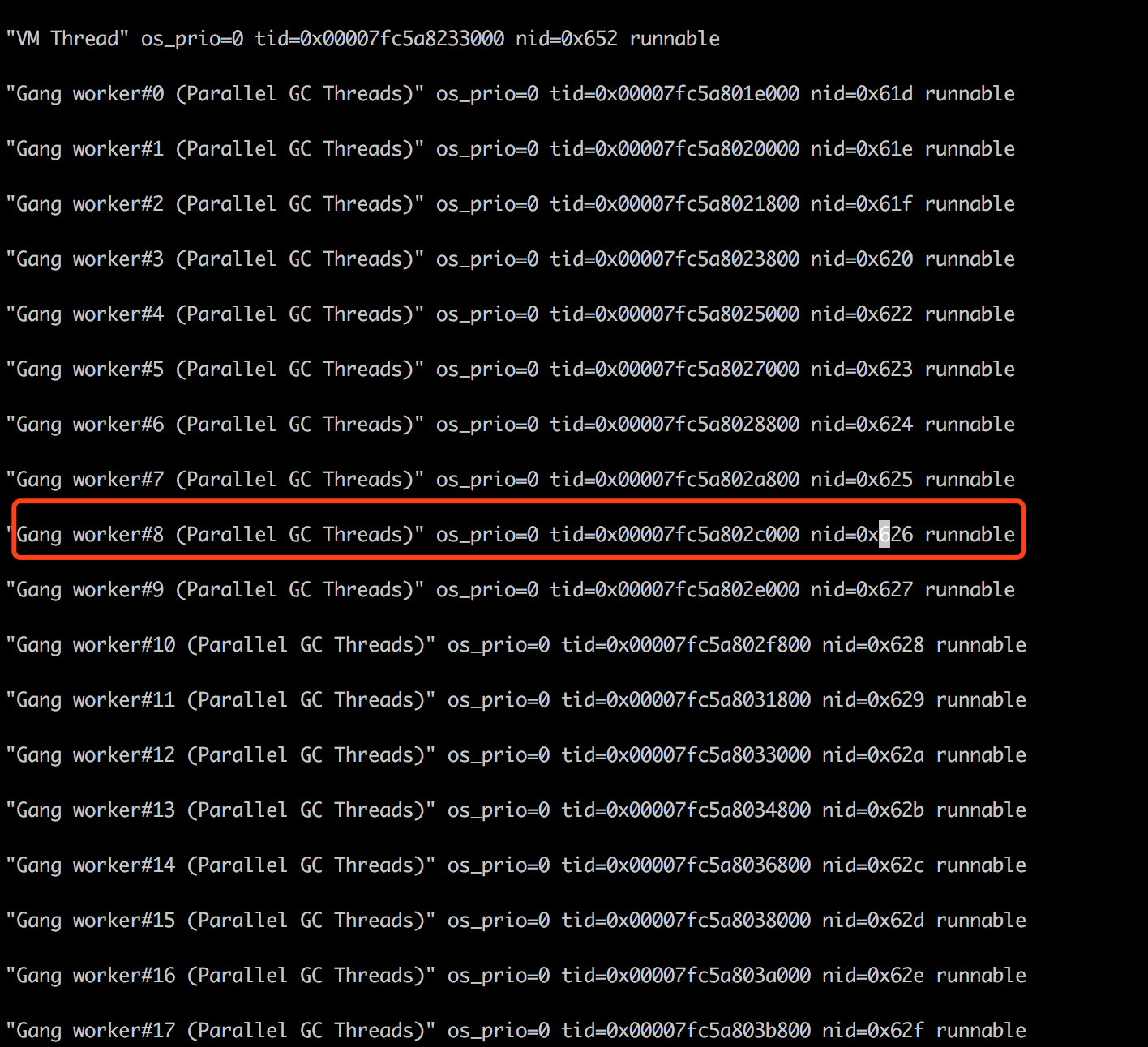
VM Thread”就是CPU消耗较高的线程。VM Thread是JVM层面的一个线程,主要工作是对其他线程的创建,分配和对象的清理等工作的。通过Jstack 出来的日志可以看出JVM正在进行大量的GC工作。
进一步通过jstat查看什么导致的大量GC.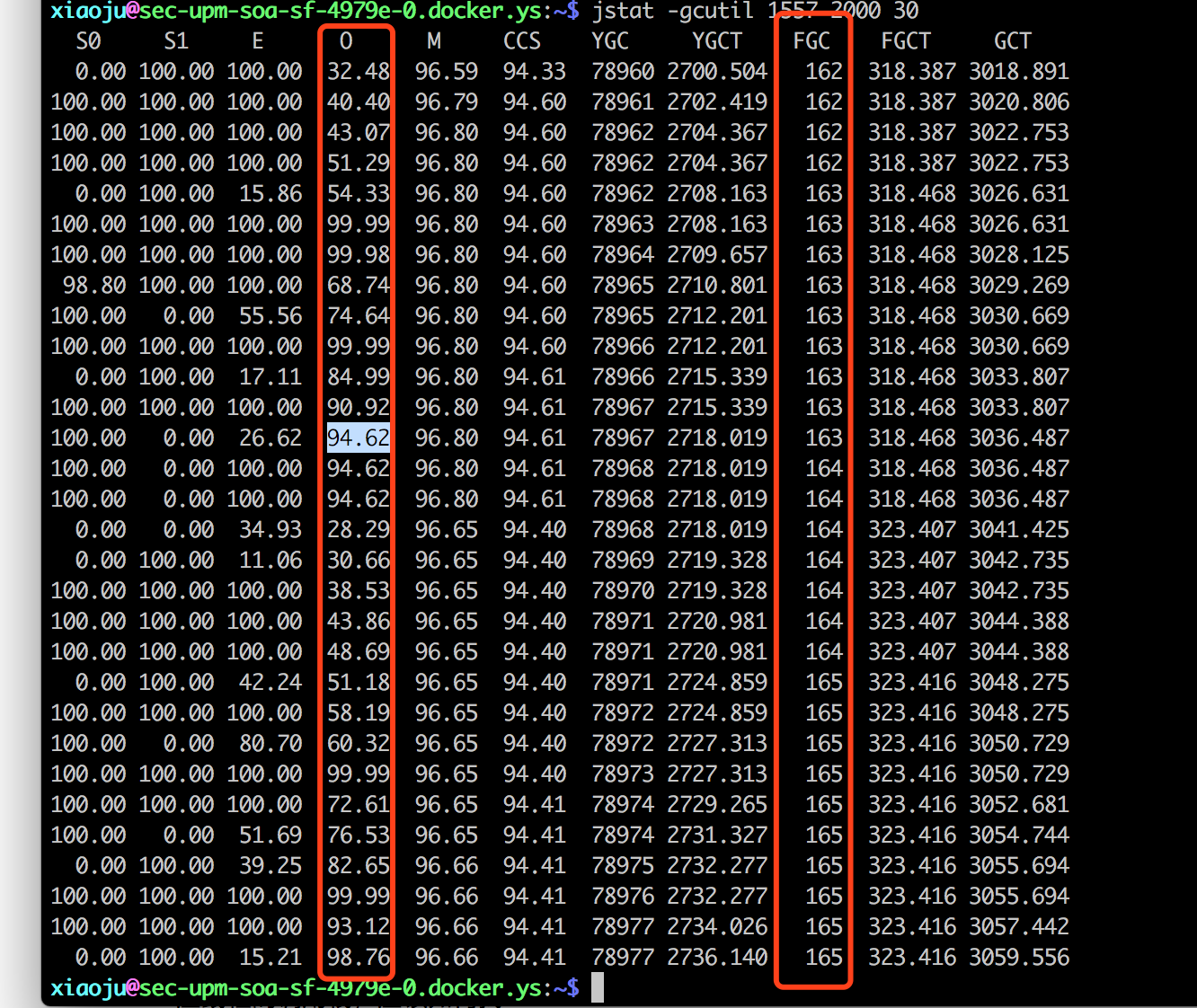
可怕的事情发现了:60s内FGC竟然触发了3次 – 即20s一次FGC的频率。要知道FGC号称stop-the-world, 10s一次FGC是对于线上服务来说是十分可怕的。频繁的出现FGC肯定是出现大对象占用了内存,YGC无法销毁堆积到了老年代,老年代不断被占满才导致FGC。
进一步通过jmap看看JVM内存中创建的对象情况: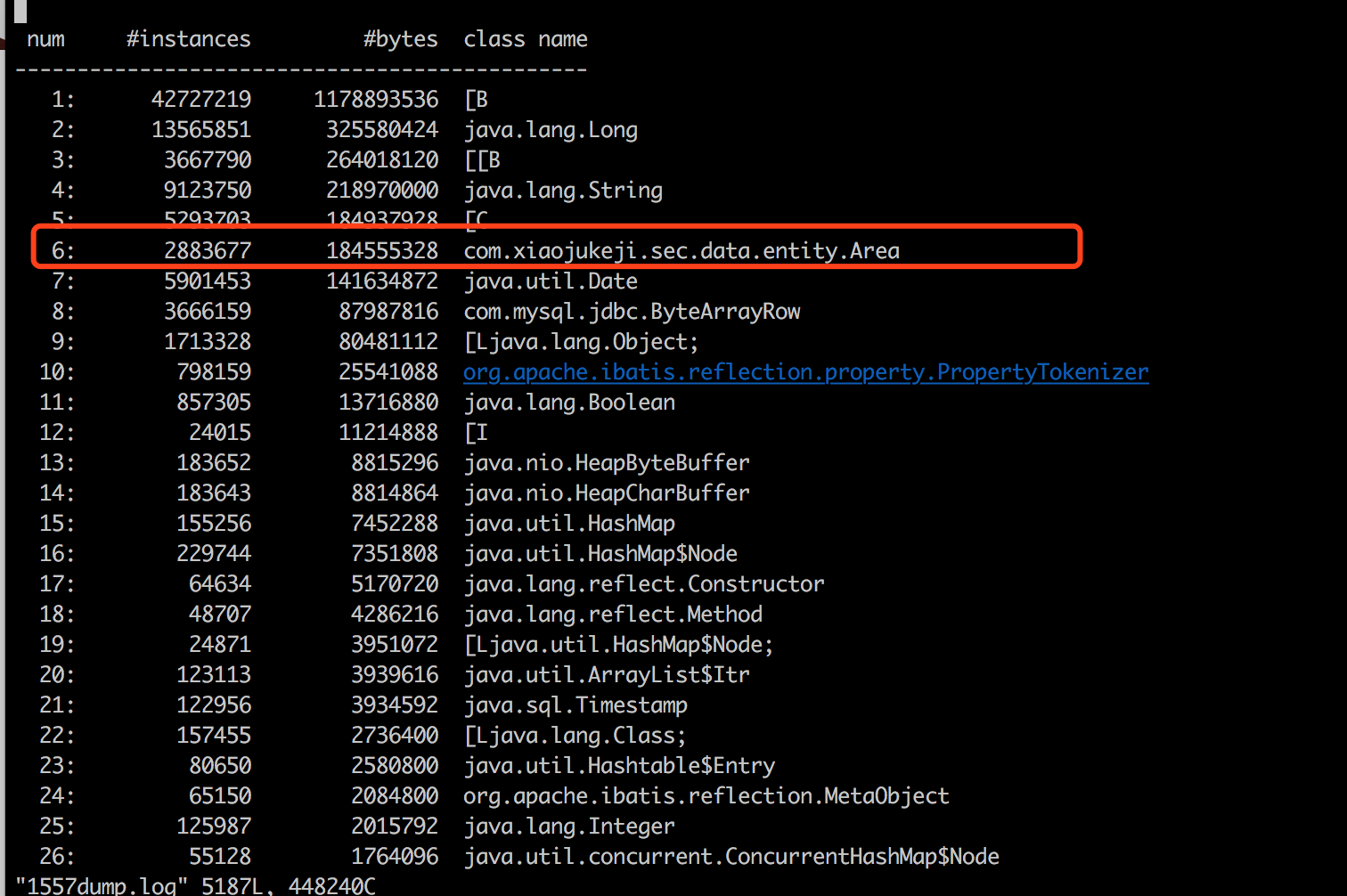
可以发现Area这个实例创建的非常多,有2883677个;总共占用内存184555326bytes, 即176M; 而单接口瓶颈值60QPS,即可导致每秒后端60个请求,也就是每秒从DB获取38000个area * 60qps = 2280000个Area对象,而不断的产生的Area对象最终导致了老年代被占满。com.mysql.jdbc.ByteArrayRow的实例也非常多3661658,无论是实例个数还是占用内存最多的是字节数组[B, 实例42727219个,占用内存1G多,这都是不正常的。再回看涉及到Area 从DB获取的代码:1
2
3
4
5
6Wrapper<Area> areaWrapper = new EntityWrapper<>();
// 致命所在!businessIds传递的是null, mybatis-plus in的输入参数为null时候默认为全部
areaWrapper.in("business_id", businessIds);
areaWrapper.eq("is_delete", IsDeleteEnums.NODELETE.getValue());
List<Area> areaList = areaMapper.selectList(areaWrapper);
select 语句返回了全表38000+条数据生成了大对象List<Area>areaList,导致com.mysql.jdbc.ByteArrayRow猛增,ByteArrayRow是缓存数据库结果的类,会产生大量的byte数组,这也解释了字节数组[B大量生成的原因。由此证明:从DB获取大量数据的操作占用了大量内存,触发了频繁的FGC.
再看此服务的内存消耗:
pmap -d 1557

实际内存占用近5G 超过了我们设置的JVM内存大小 4G (jvm_args=-Xmx4g -Xms4g)
总结
此次故障原因为:/user/get/permissions(由于历史原因是一个一直性能不高但是没有调用量的接口,一直未受到重视)此次接口QPS陡增了10倍,即增加到20qps左右,服务内部执行了大量的返回全Area表数据操作,触发了频繁的FGC会致使对内计算延迟,对外请求积压,导致服务整体雪崩。
反思
- 慎用mybatis-plus的in(null),一定要校验入参是否是null, 返回全表数据是十分消耗性能的操作。
- CPU idle 迅速掉很有可能是某个接口当调用量大的时候性能变差,触发了频繁的FGC.
- 限流一定要加到所有接口上,木桶原理。
- 服务一定要加FGC频繁的报警,当触发频繁FGC,一定是服务性能达到瓶颈了。