
最近被问到一个问题,你们服务的YGC的时间是多少?不看不知道,一看吓一跳系列。
现象
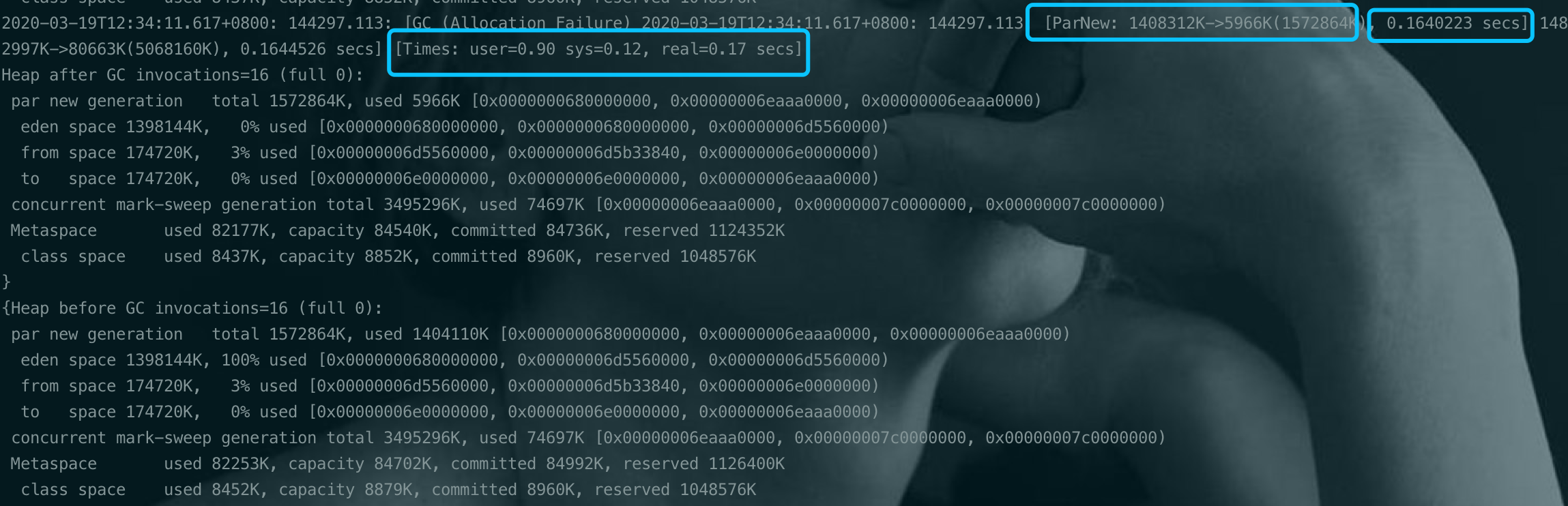
YGC时间达到百ms(170ms).
我们JVM的基本配置为:1
-Xmx5g -Xms5g -XX:MetaspaceSize=128m -XX:MaxMetaspaceSize=128m
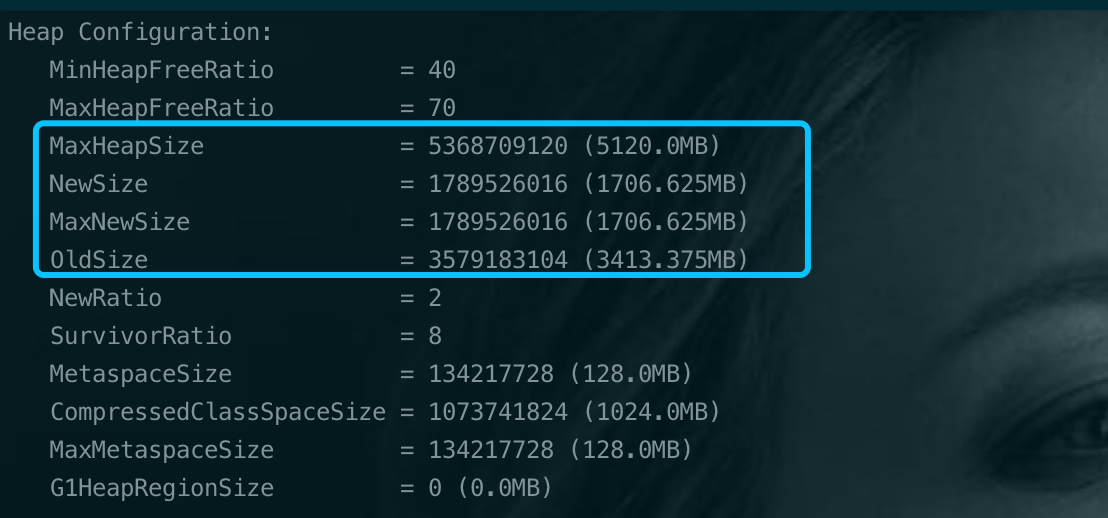
年轻代和老年代的比例没有额外配置,NewRatio=2,即新生代 ( Young ) 与老年代 ( Old ) 的比例的值为 1:2。 通过上图也可以看出来,年轻代1.67G,老年代3.33G。GC并发线程数使用的默认26.
排查及优化
通过看YGC日志可以发现回收效率还是可以的 [ParNew : 1408312K -> 5966K], 所以猜测YGC的时间高的原因是YGC空间太大了, 但是也不能光把年轻代调小,5G堆内存年轻代小了,老年代就非常大,可能带来FGC时间更长的副作用。于是想到5G的堆内存也是不小。不小这个太“感性”的说了,直接定量研究。看使用率。
可以看到年轻代使用率只有20%, 老年代使用率只有2.15%。可以说JVM堆的内存使用率很低了。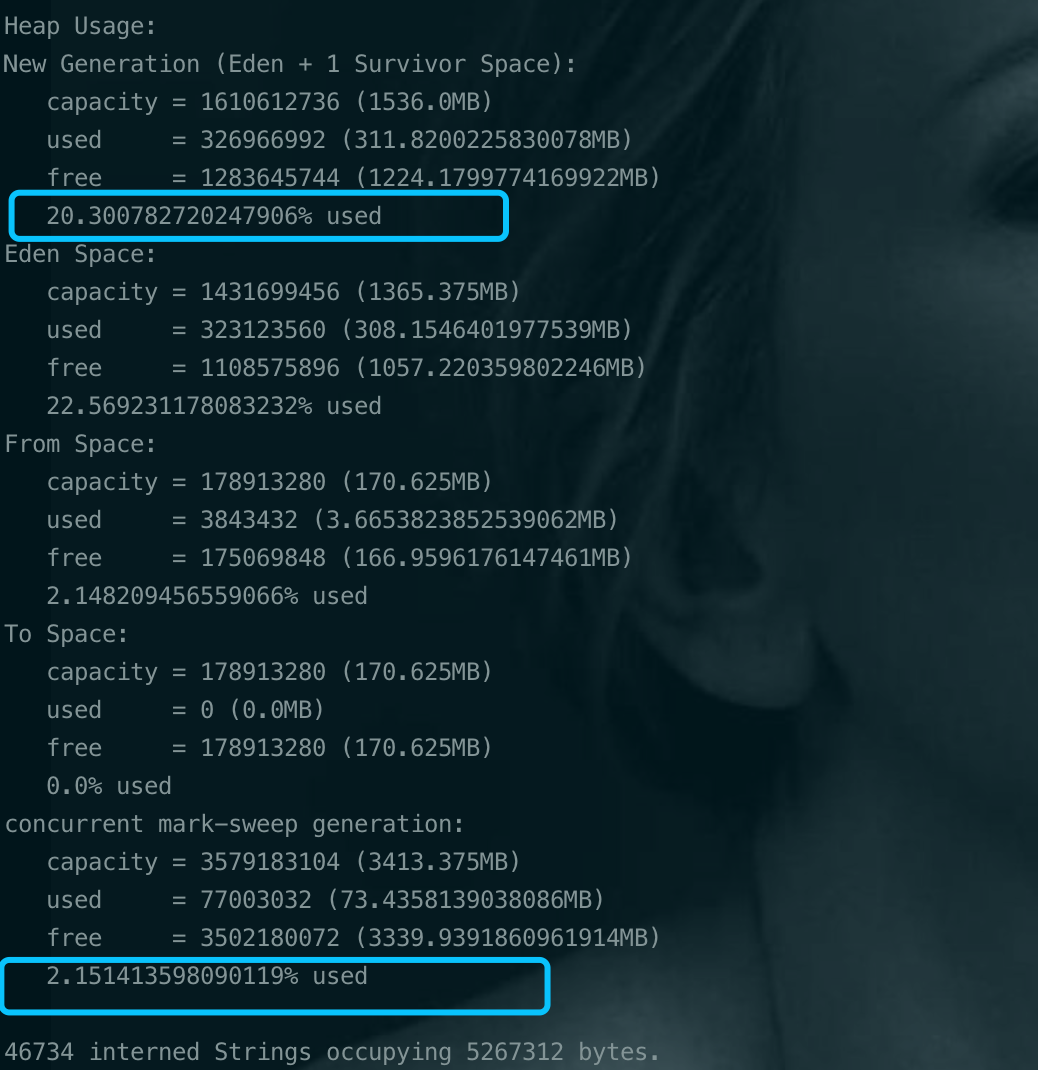
想起之前看到的一些JVM参数理论探讨JVM内存设置多大合适?Xmx和Xmn如何设置?
Java 整个堆大小设置,Xmx 和 Xms 设置为老年代存活对象的3-4倍,即FGC之后老年代内存占用的3-4倍。
年轻代Xmn 的设置是老年代存活对象的1-1.5倍。
老年代内存设置是老年代存活对象的2-3倍。BTW:
1、Sun官方建议年轻代的大小为整个堆的3/8左右, 所以按照上述设置的方式,基本符合Sun的建议。
2、堆大小=年轻代大小+年老代大小, 即xmx=xmn+老年代大小 。 Permsize不影响堆大小。
3、为什么要按照上面的来进行设置呢? 没有具体的说明,但应该是根据多种调优之后得出的一个结论。
程序运行稳定时查看老年代使用大小,约100M,如图:
严格按照这个比例配置,堆的大小应该是100M*4,约等于400M。我们服务是docker独占的服务(4core8G),倒也没必要调到这么小。于是先把机器docker10的配置调整为1G看看,1
-Xmx1g -Xms1g -XX:MetaspaceSize=128m -XX:MaxMetaspaceSize=128m
与此同时,因为我们线上机器是多台docker。我设置了另外一台docker11,docker12作为对照组,另外还有docker13/docker14是老配置(2G)。
docker11 配置:1
-Xmx1g -Xms512m -XX:MetaspaceSize=128m -XX:MaxMetaspaceSize=128m
docker12 配置:1
-Xmx2g -Xms2G -XX:MetaspaceSize=128m -XX:MaxMetaspaceSize=128m
整体配置对照组如图: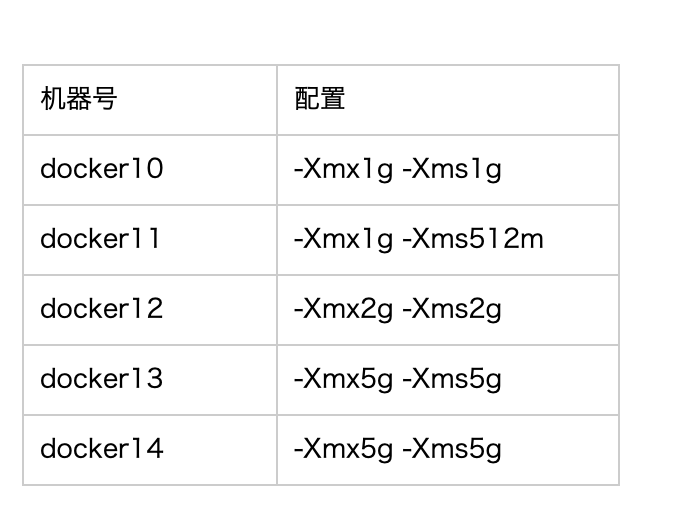
第二天早上大概隔了11h看看效果,之所以等着么久是想让程序跑稳定点。效果如监控图:
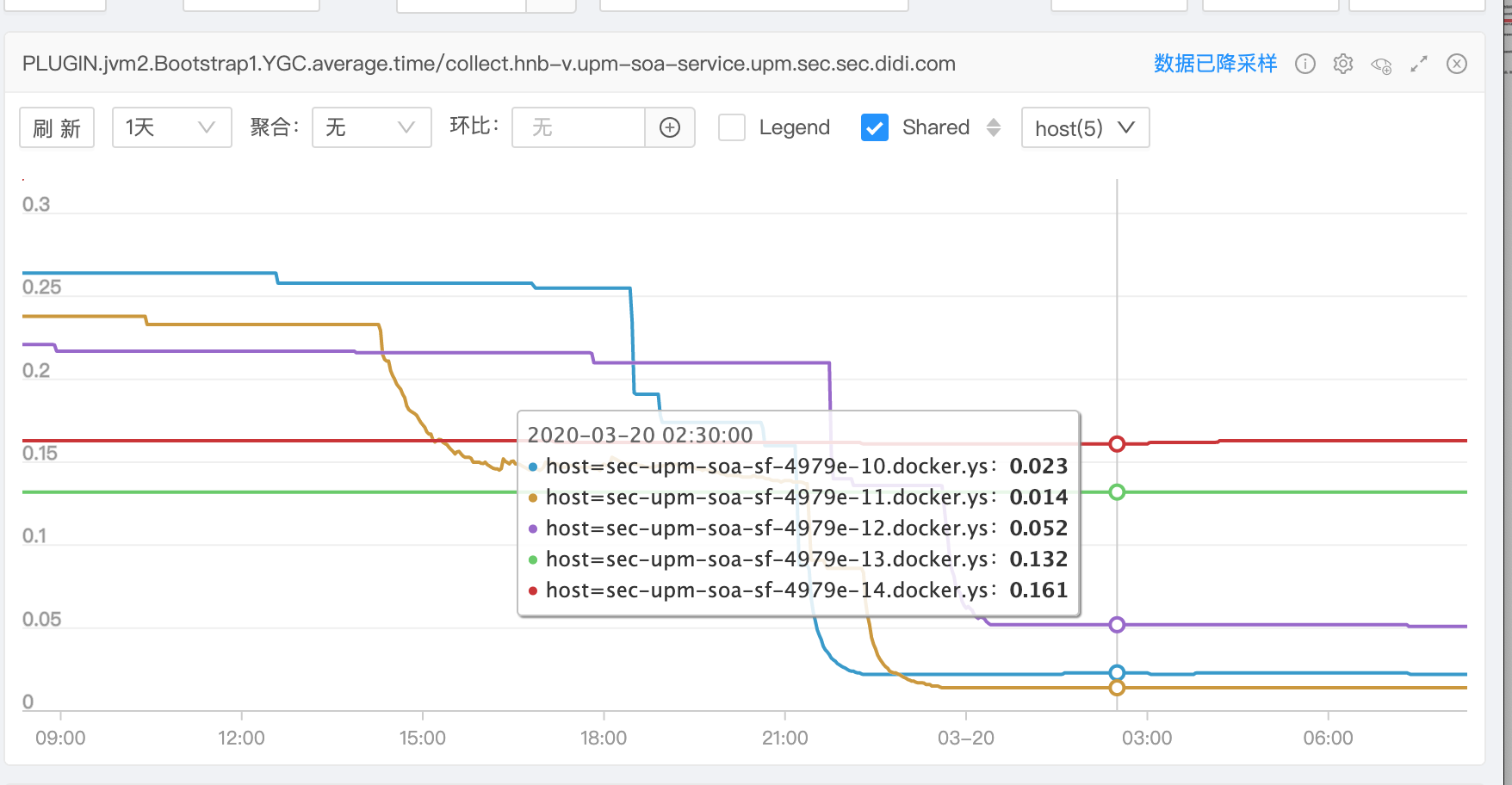
docker10: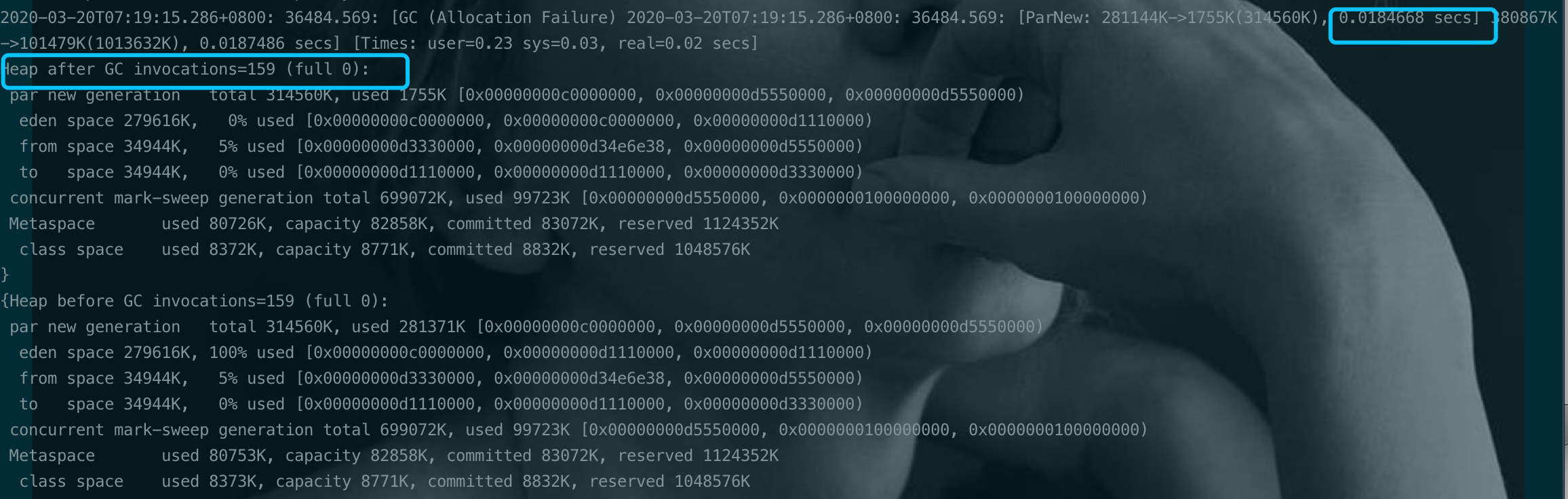
docker11:
而老配置docker13-docker14通过看gc日志,YGC次数也就不过5次。
可以看出当把堆空间设置相对较小后,YGC次数增加,但是每次YGC的时间少了,由百级ms 降到10ms左右。这真是频率和时间的博弈…YGC时间太长有可能造成接口卡顿,太频繁也可能造成接口受影响。
YGC也会Stop the world.所以还是认为之前设置的5G空间有点浪费内存了,而且YGC时间过长。
结论
将服务的JVM参数配置为:1
-Xmx1g -Xms1g -XX:MetaspaceSize=128m -XX:MaxMetaspaceSize=128m