
内存结构
顾名思义,PoolArena负责缓存池的全局调度,它负责在上层组织和管理所有的chunk以及subpage单元。为了减少多线程请求内存池时的同步处理,Netty默认提供了cpu核数*2个PoolArena示例。
We use 2 available processors by default to reduce contention as we use 2 available processors for the number of EventLoops in NIO and EPOLL as well. If we choose a smaller number we will run into hot spots as allocation and de-allocation needs to be synchronized on the PoolArena.
1 | final int defaultMinNumArena = NettyRuntime.availableProcessors() * 2; |
PoolArena 内部对chunk与subpage的内存组织方式如下图:
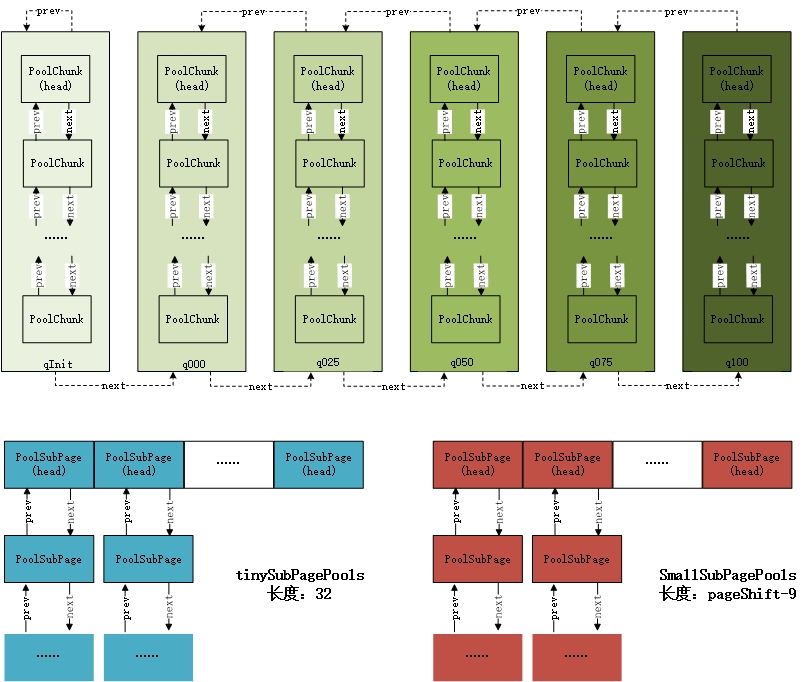
每个PoolArena管理的所有chunk根据内存使用率的不同被划分为6种类型,以双向链表ChunkList的方式组织,并在不断的内存分配过程中根据chunk的使用率,对chunk的类型进行调整,放入合适的链表中。
在文章Netty 是怎么做内存管理-PoolSubpage中,我们已经了解到,subpage是针对请求内存小于一个页面大小时的内存划分。根据请求内存大小,subpage有可以被分为,smallpage(>=512 btyes)和tinypage(<512 bytes)两种类型。在内存分配的过程中,为了保持subpage中内存的连续性,避免内存碎片,并方便根据内存偏移量进行定位,每个页面内分配的内存段应该具有统一的规格(PoolSubpage中的elemSize)。
如上图所示,类似的chunk,PoolArena把subpage以数组的方式组织起来,把相同elemSize的subpage组成一个链表,放入数组中。由于subpage最小的内存段被限定为16bytes,所以tinysubpages共占据512/15=32个数组位置,而smallsubpage则在512的基础上依次翻倍,直到一整个页面大小,所以smallsubpages共有 log(pageSize/512)=pageShifts-9 个数组元素。
内存分配
整体流程
PoolArena分配的入口代码如下:
1 | private void allocate(PoolThreadCache cache, PooledByteBuf<T> buf, final int reqCapacity) { |
代码的流程比较清晰:
- 对请求的内存大小做规整化处理:大于chunkSize时调整为保持内存对齐即可;大于512时调整为大于等于请求值的2的最小幂;小于512调整为大于等于请求值的16的倍数
- 当请求内存小于pageSize时,在页内分配:请求内存小于512在tinysubpages数组中定位并执行分配,大于512时在smallpages数组中定位并执行分配,当数组中没有可用的内存页时,在chunk中寻找新的内存页进行分配。
- 请求内存大于pageSize小于chunkSize,在chunk内执行分配
- 请求内存大于chunkSize,直接调用allocateHuge分配,不在内存池中管理。
当然除了上述整体流程,还有一些细节上的实现需要我们深挖:如何根据请求内存的大小在subpages数组中定位?当需要在chunk中执行分配时,在chunkList中选择哪个chunk?分配完成后,如何使用返回的内存偏移量句柄对Bytebuf进行初始化?依次来看:
页面定位
页面定位主要解决的是根据请求内存的大小,如何选择合适的subpage来进行分配的问题。首先来看tinysubpages:
1 | static int tinyIdx(int normCapacity) { |
我们已经知道,tinysubpages管理的内存段自16byte开始,以16byte依次递增自512,共映射到32个数组元素中,所以按照请求内存的大小除以16即可完成定位。
1 | static int smallIdx(int normCapacity) { |
smallsubpages的定位也不难理解,计算请求内存相对于1024的倍数即为相应的数组下标。
Chunk定位
回顾前述的内存结构,PoolArena根据内存使用率的情况把Chunk分成了6种类型:qInit,q000,q025,q50,q075,q100, 他们所对应的chunk使用率如下表:
| Type | Usage |
|---|---|
| qInit | [Integer.MIN_VALUE, 25) |
| q000 | [1, 50) |
| q025 | [25, 75) |
| q050 | [50,100) |
| q075 | [75,100) |
| q100 | [100,Integer.MAX_VALUE) |
这里有一点需要注意的就是,相邻的ChunkList之间在使用率上存在一定的重叠区域,即一个chunk的使用率为35的chunk可能存在于q000中,也可能存在于q025中。这主要是为了防止,由于使用率不断变化,导致某个chunk在两个List中不停来回跳动的情况,加了这么一段重叠的缓存区域,可以减少跳动的次数。详细可以参考链接中的分析。
1 | private void allocateNormal(PooledByteBuf<T> buf, int reqCapacity, int normCapacity) { |
首先尝试在已经发生分配的ChunkList中,进行分配,如果有可用的chunk则直接返回,否则新建一个chunk,执行分配并初始化ByteBuf。新创建的Chunk将就被加入qInit链表中。
在qxxx中执行分配的过程比较简单,此处不再附上代码,其流程可以描述为:从ChunkList的链表头开始遍历,找到第一个可以分配的Chunk,并初始化ByteBuf,最后依据Chunk的使用率,判断是否需要将Chunk加入下一个ChunkList中。
对于Netty选择ChunkList时候的顺序,摘抄文章中的下面一段分析:
分配内存时,为什么不从内存使用率较低的q000开始?在chunkList中,我们知道一个chunk随着内存的释放,会往当前chunklist的前一个节点移动。
q000存在的目的是什么?
q000是用来保存内存利用率在1%-50%的chunk,那么这里为什么不包括0%的chunk?
直接弄清楚这些,才好理解为什么不从q000开始分配。q000中的chunk,当内存利用率为0时,就从链表中删除,直接释放物理内存,避免越来越多的chunk导致内存被占满。
想象一个场景,当应用在实际运行过程中,碰到访问高峰,这时需要分配的内存是平时的好几倍,当然也需要创建好几倍的chunk,如果先从q0000开始,这些在高峰期创建的chunk被回收的概率会大大降低,延缓了内存的回收进度,造成内存使用的浪费。
那么为什么选择从q050开始?
1、q050保存的是内存利用率50%~100%的chunk,这应该是个折中的选择!这样大部分情况下,chunk的利用率都会保持在一个较高水平,提高整个应用的内存利用率;
2、qinit的chunk利用率低,但不会被回收;
3、q075和q100由于内存利用率太高,导致内存分配的成功率大大降低,因此放到最后;
ByteBuf初始化
对ByteBuf的初始化就是告诉ByteBuf,他可以使用的内存起点位置offset,请求内存的位置length和最大可用内存的位置maxLength。
1 | void initBuf(PooledByteBuf<T> buf, long handle, int reqCapacity) { |
1 | private static int memoryMapIdx(long handle) { |
在PoolChunk或者PoolSubpage完成分配后,都会返回一个内存偏移量句柄handle作为标识。在执行初始化时,就是依据handle逆向初始化的过程。
PoolChunk返回的handle就是分配的内存在memoryMap中的节点编号,而PoolSubpage返回的handle中,低32表示当前page在chunk中的编号,高32包含了分配的内存段在bitmap中的索引。
所以,在handle中取低32位就能计算得到分配的内存在chunk中的节点编号,而取高32位信息就能计算得到分配的内存段在subpage中位图的索引位置。
首先来看一下基于chunk的分配(buf.init),ByteBuf三个内存参数的计算方式:
offset
offset = runOffset(memoryMapIdx)+offset
最后一个offset是初始化chunk时预留的offset,默认是0。重点看runOffet函数:1
2
3
4
5
6
7
8
9
10private int runOffset(int id) {
// represents the 0-based offset in #bytes from start of the byte-array chunk
int shift = id ^ 1 << depth(id);
return shift * runLength(id);
}
private int runLength(int id) {
// represents the size in #bytes supported by node 'id' in the tree
return 1 << log2ChunkSize - depth(id);
}
shift的计算方式与Netty内存管理-PoolSubpage一文中,计算叶子节点相对位置的方式相同。简单回顾一下,如图:
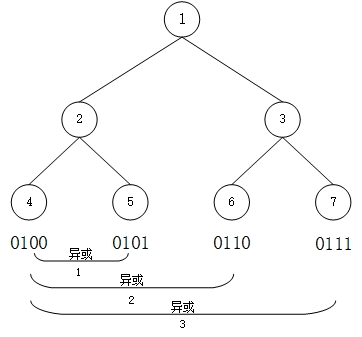
由完全二叉树的性质,每一层首节点的编号为2depth, 而当前层其他节点的编号则从左到右依次加1,所以当前层任意节点相对于首节点的位置,可以通过节点编号的异或运算去除高位的1计算得到。
所以shift表示了,当前节点相对于其所在层的首节点的相对位置(从0开始计算)。
runLength表示了当前节点所在层里,每个节点拥有的内存大小值,所以shift*runLength即为当前节点在chunk中的相对位置偏移量。
length
length即为用户请求的内存大小:reqCapacity。
maxLength
maxLength = runLength(memoryMapIdx), 由于把当前节点都分配给了ByteBuf的最大可用内存就是一个节点所拥有的内存大小。
类似的,看一下基于subpage的分配:1
2
3
4
5
6
7
8
9
10
11
12
13
14private void initBufWithSubpage(PooledByteBuf<T> buf, long handle, int bitmapIdx, int reqCapacity) {
assert bitmapIdx != 0;
int memoryMapIdx = memoryMapIdx(handle);
PoolSubpage<T> subpage = subpages[subpageIdx(memoryMapIdx)];
assert subpage.doNotDestroy;
assert reqCapacity <= subpage.elemSize;
buf.init(
this, handle,
runOffset(memoryMapIdx) + (bitmapIdx & 0x3FFFFFFF) * subpage.elemSize + offset,
reqCapacity, subpage.elemSize, arena.parent.threadCache());
}
由于subpage是chunk的叶子节点,所以首先需要根据memoryMapIdx定位到chunk中具体的哪一页:1
2
3private int subpageIdx(int memoryMapIdx) {
return memoryMapIdx ^ maxSubpageAllocs; // remove highest set bit, to get offset
}
maxSubpageAllocs表示chunk中最多有多少个页面,由于完全二叉树的性质,其值与首个叶子节点的编号一致,所以可以计算出当前叶子节点的相对位置。
offset
runOffset(memoryMapIdx) + (bitmapIdx & 0x3FFFFFFF) * subpage.elemSize + offset
runOffset与前面基于chunk的分配含义相同,计算得到当前叶子节点在chunk中的内存偏移;(bitmapIdx & 0x3FFFFFFF) * subpage.elemSize 利用位图索引bitmapIdx计算分配的内存段在位图中的实际位置,此处与0x3FFFFFFF按位与是为了去除在构造handler时添加的高位1。用页的内存偏移加上页内偏移地址,即可得到分配的内存段全局的相对内存位置。
length
length即为用户请求的内存大小:reqCapacity。
maxLength
当前页面内存段的大小:elemSize
自此,基于内存池的内存分配逻辑以全部梳理完成。