
在《Redis RDB持久化》一文中,我们对RDB持久化的流程,格式以及实现方式进行了阐述。本文重点关注下另外一种持久化方式:AOF持久化。
初始AOF
与RDB将整个内存快照写入文件的方式不同,AOF以协议文本的方式,将所有对数据库进行过写入的命令(及其参数)记录到 AOF 文件,以此达到记录数据库状态的目的。
1 | reids> RPUSH list 1 2 3 4 |
执行上述命令后生成的快照文件如下:
1 | *2 |
AOF命令协议
由于在我们执行的指令中,有4条对数据库执行内容变更的操作,最终写入aof文件的也只有4条。
AOF存储一条命令的格式如下:
1 | *<count> /*接下来的命令有count个参数*/ |
完全符合示例中生成的aof文件内容。需要指出的就是第一条SELECT命令是Redis自己加上的,为了保证两条相邻的指令操作了不同的内部数据库时,能够正确的区分。
AOF实现原理
简单的来说,AOF的实现原理就是基于配置项”appendonly yes/no”来控制是否将更新命令写入appendonly文件,如果设置为yes,则每次数据更新的命令都会被追加到内存缓存server.aof_buf里,然后根据配置项appendfsync,决定何时将aof_buf刷盘。下面就看看此流程中的实现细节。
Append aof_buf
追加aof_buf的入口函数在feedAppendOnlyFile中,具体的执行流程如下图: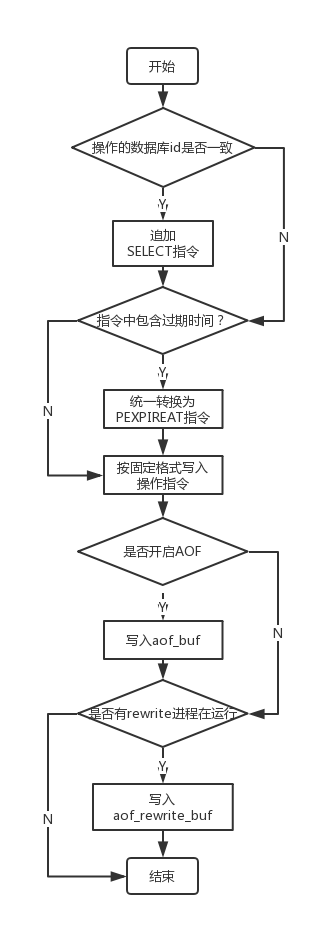
- 如果当前更新操作和上一次aof记录操作的数据库不一致,则自动生成一个SELECT命令,控制选择正确的数据库
- 如果当前操作指令中包含expire信息,如setex,expire等,需要特殊处理把设置到期时间的功能统一使用PEXPIRE命令记录
- 按照AOF命令协议的格式,拼装当前操作的核心指令
- 如果系统开启了写AOF的配置,则将拼装的命令写入buf;如果有在运行的rewrite子进程(参见下一小节的AOF重写),为了记录rewrite期间的数据差异,还需要将指令追加到aof_rewrite_buf中。
Flush aof_buf
刷盘流程
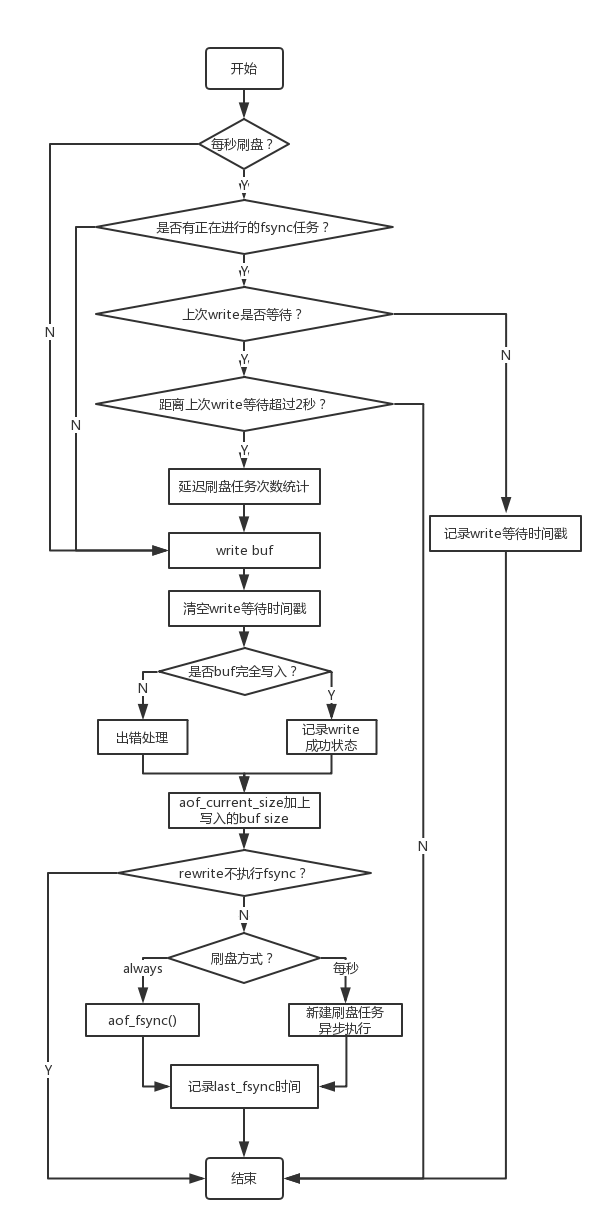
刷盘的流程整体上分为write()将aof_buf写入系统缓存以及fsync写磁盘两个步骤。首先,在设置了每秒flush一次aof_buf配置情况下,如果后台有正在运行的fsync任务,并且距离上次write等待没超过2秒,直接返回,等待上一次延迟的任务执行完成。否则,调用aofWrite循环write()。由于无法保证write()一定成功,所以当写入不完全时,会执行特定的出错处理机制。如果完全写入,表示aof_buf的内容已写入系统缓存,此时增加aof_current_size的计数。到此为止,就完成了通过write调用将aof_buf写入系统缓存的工作。一旦系统缓存写入成功,即使Redis程序崩溃或者退出,只要系统正常运行,那么aof_buf也一定能刷入磁盘中。
如果aof文件fsync的策略配置为AOF_FSYNC_ALWAYS,则直接在当前主进程中执行一次fsync,如果fsync的策略配置为AOF_FSYNC_EVERYSEC,并且后台没有正在执行的fsync任务,则为aof文件的fd创建一个新的fsync任务在后台异步执行。
AOF_FSYNC_ALWAYS和AOF_FSYNC_EVERYSEC两种刷盘策略是在安全性和效率之前的不同取舍方案。
- AOF_FSYNC_ALWAYS能保证每次执行的命令都会同步的写入内核缓存和同步磁盘,但每次操作都需要在主进程中写缓存写磁盘,势必会影响Redis处理后续指令的速度。
- AOF_FSYNC_EVERYSEC的策略下,异步刷盘和延迟等待的功能,减小了写AOF对Redis主进程执行命令的影响,同时保证最多丢失2s内的操作数据。但由于fsync和write调用都是阻塞的,比如出现写磁盘被阻塞时,那么后续write调用因为都操作相同的文件描述符也会相应的等待,进而影响整个Redis主流程的执行。
异步刷盘
由于fsync操作可能阻塞主流程的执行,所以Redis使用了一个独立的线程来处理异步fsync文件到磁盘的工作。Redis对所有需要异步线程操作的任务做了一个统一的封装,代码在bio.c文件中。实现的逻辑也比较简单,针对目前支持的close_file, aof_fsync, lazy_free三种后台任务,各启动一个线程并分配一个任务队列。线程循环等待任务并执行,最后修改任务的等待状态。
刷盘时机
Redis源码中调用flushAppendOnlyFile执行flush aof_buf的地方一共有4个:
- 服务器主进程处理完本次IO和时间事件后,等待下一次事件(epoll_wait)到来之前
- 服务器定时器serverCron中,默认每秒执行一次
- 服务器退出之前的准备工作prepareForShutdown(),执行一次强制刷盘
- 通过配置指令关闭AOF功能时,执行一次强制刷盘
在第一种情况下,服务器在处理客户端请求的操作指令时,如果涉及到数据库内容的更新,并且配置开启了AOF功能,那么上一小节的feedAppendOnlyFile将会被调用,把操作命名以协议格式追加到buf中。在服务器完成进入下一次时间循环之前,flushAppendOnlyFile会被执行一次。
从刷盘流程的流程图中,不难看出,写aof_buf到内核缓存在一次flushAppendOnlyFile的调用中不一定会执行(阻塞或者2s内的延迟等待)。如果后续一直没有新的事件到来,那么本次写入aof_buf的操作就有丢失的可能。所以在服务器每秒一次的定时任务中,会根据当前是否有被延迟执行的刷盘操作以及写aof_buf出错1秒后重试等条件,触发一次对flushAppendOnlyFile的调用。
后面两种case比较类似,都是在正常退出之前,强制执行一次刷盘。强制执行的时候会忽略前面等待的任务而直接写内核缓存并创建新的刷盘任务。
AOF Rewrite
为什么要rewrite
AOF文件只是简单的存储了写操作相关的命令,而并没有进行合并。随着Redis服务器在运行过程中不断接受命令,如果Redis只是将客户端修改数据库的命令存储在AOF文件中,AOF文件会急剧膨胀而导致效率低下(AOF文件越大,占用存储空间越大,数据还原过程耗时越多)。所以Redis提供了一种rewrite的机制,以当前数据库的数据空间为终态,压缩重写AOF文件。Rewrite可以理解对同一个key先后modify的指令合并为一条指令的过程,具体的实现流程就是遍历当前数据库的键空间,将每个key对应的对象用一条命令来表达并保存到AOF文件中。
Rewrite的具体流程
由于rewrite操作需要访问整个内存数据库,与RDB持久化类似,为了防止数据访问的冲突,Redis也fork了一个新的子进程来独立的完成rewrite的过程。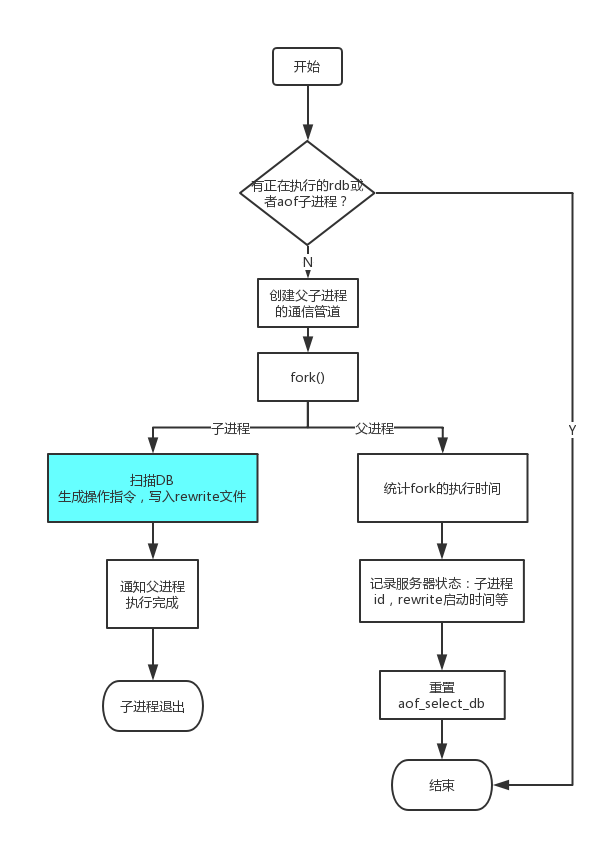
- 因为子进程可能会对父进程做一份完整的内存拷贝,为了减少大规模内存拷贝的次数并防止内存被占满,如果有正在运行的RDB子进程,直接返回。否则执行步骤2
- 父进程创建管道,并监听子进程给父进程同步数据管道上的可读事件。
- fork子进程。子进程执行步骤4,父进程执行步骤5。
- 子进程开始扫描从父进程copy来得内存数据,并生成相应的set指令,写入rewrite文件,最后通知父进程执行完成,子进程退出。
- 父进程做一些统计和设置状态的工作,由于父进程已经将管道加入了事件监听器中,所以父进程可以直接返回,无需再等待子进程执行完成。
在aof_rewrite的父子进程模型中,存在两类管道:第一种是与rdb持久化执行过程中提到的父进程用于监听子进程正常退出的通信管道。由于子进程只能获取到fork()之前的内存数据,为了保持最终录入结果的正确性,在rewrite期间父进程新产生的操作指令也需要通过给子进程写入rewrite文件。这就是第二类管道,专门用于同步差异数据的。回顾Append aof_buf小节aof_rewrite_buf就是父进程用于缓冲差异数据,并最终通过管道同步给子进程的。前述流程中提到的管道都是第二类管道。第二类管道包含3对双向管道,分别用于:父进程给子进程同步数据的读写管道,子进程给父进程同步状态用的读写管道,父进程确认收到子进程数据的读写管道。
我们注意到在父进程返回之前,把当前aof_select_db重置为-1,这是为了保证下一次调用feedAppendOnlyFile()记录操作命令的时候就会强制生成一条SELECT指令,保证父进程同步给子进程的数据能够安全地合并到rewrite文件中。
下面就来看一些rewrite文件生成的具体流程,即上流程图中蓝色标记的具体实现方式: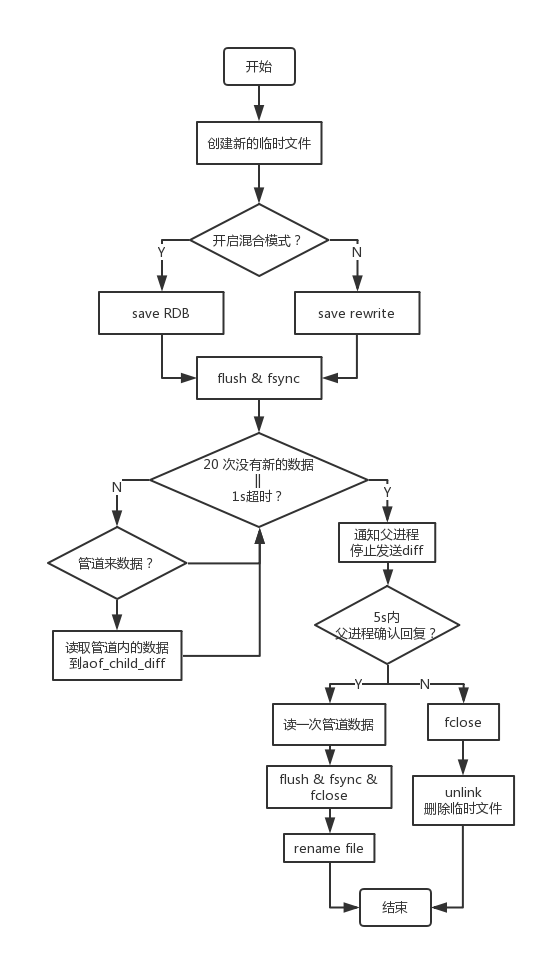
- 创建新的临时文件
- Redis 4.0新加入了混合模式的持久化文件,综合了RDB文件内容更紧凑恢复更快,AOF机制更安全耐久的优点。如果开启了混合模式,则先用RDB格式将内存快照写入文件(恢复的时候,识别RDB的协议头可以判断是否是混合模式)。否则,遍历整个内存数据空间,根据相应的key-value类型,生成对应的set命令,写入文件。
- 由于父进程可能还在持续的发送差异数据,所以先执行一次刷盘,完成大部分数据的写入,使下一次差异指令的刷盘过程更快。
- 持续等待并读取父进程从管道写入的差异数据,直到20ms内没有新的数据到来或者已经等待了1s后退出循环。
- 利用管道通知父进程停止发送差异数据,并开始同步等待父进程确认收到停止发送的指令。如果5秒内父进程没有响应则执行步骤6,否则执行步骤7。
- 关闭创建的临时文件描述符,删除临时文件退出,本次rewrite失败。
- 再从管道读取一次数据,确保收到父进程停止发送差异前的所有数据。刷盘,关闭文件描述符,并通过rename原子性的完成临时文件的重命名到指定的目标文件中。
Rewrite时机
Rewrite的触发机制主要有一下三个:
- 手动调用bgrewriteaof命令,如果当前有正在运行的rewrite子进程,则本次rewrite会推迟执行,否则,直接触发一次rewrite;
- 通过配置指令手动开启AOF功能,如果没有rdb子进程的情况下,会触发一次rewrite,将当前数据库中的数据写入rewrite文件;
- 在Redis定时器中,如果有需要退出执行的rewrite并且没有正在运行的rdb或者rewrite子进程时,触发一次或者aof文件大小已经到达配置的rewrite条件也会自动触发一次。
这里重点看一下,Redis基于aof文件大小,自动触发rewrite的策略:
1 | /* Trigger an AOF rewrite if needed. */ |
从代码中不难看出,在开启了aof功能并且没有正在运行的rdb或者rewrite子进程时,触发rewrite需要满足两个条件:
- 当前aof文件的大小超过了配置的aof_rewrite文件大小的最小基准值;
- aof当前文件大小相对于上一次rewrite后aof文件大小的增长率,超过了配置的比例;
AOF Rewrite父子进程通讯模型
在上一节中,我们从rewrite子进程的视角,介绍了具体的流程和出发时机,这一节,我们将从更高层的视角,来看一下整个rewrite过程中父子进程通讯的模型以及父进程在一些问题上处理细节。

整个rewrite过程中,父子进程的通讯模型如上图。前面章节我们主要从右边子进程的维度,分析了整个执行流程。那么从父进程的角度,我们仍需要解决以下问题:
- 如何有效的同步rewrite过程中的差异数据给子进程;
- 如何有效的监听子进程同步过来的数据,实时的响应处理;
- 子进程退出后,如何需要执行哪些善后处理
同步指令
在rewrite子进程运行过程中,随着客户端请求命令的不断到来,父进程在feedAppendOnlyFile调用的最后,会将组装过了协议指令,先追加到缓存中,然后通过管道同步给子进程。由于主进程不能等待写管道完成才继续执行,所以需要缓存先存储这些需要同步给子进程的数据。为了避免realloc调用,触发的大规模内存拷贝,Redis对这部分数据,通过一个内存块aofrwblock的链表来维护,默认大小10M。
追加数据到缓存的时候,首先在链表尾部的内存写入数据(不够就再创建新的内存块),同时在管道(上图的diff_data)上注册写事件,通过事件循环触发管道数据的写入。
核心的写管道代码如下:
1 | while(1) { |
监听管道
父进程对子进程响应管道child_ack的监听在管道创建的时候就注册了可读事件的处理函数。子进程写入数据后基于Redis的事件触发机制,回调该处理函数即可。
善后处理
与RDB的父子进程执行模式一致,在子进程执行结束后,会通过管道(存储在server的结构体中)向父进程发送一些统计数据。在接收到子进程结束的通知后,除了清理子进程的状态和统计信息,最重要的工作是将子进程生成的aof临时文件,替换到配置的aof持久化文件中。为了保证替换的原子性,rename将会被调用。当我们用新的临时文件替换旧的aof文件时,存在以下两种场景会导致主进程的阻塞:
- aof功能被关闭,主进程不再持有旧aof文件的文件描述符(server.aof_fd=-1), 当使用临时文件rename旧的aof文件后,由于没有进程再占用它,所以会触发操作系统unlink,即删除该文件的操作,这会阻塞主进程;
- aof功能仍旧开启,主进程虽然继续持有旧aof文件的描述符,rename不会触发unlink, 但当执行完文件替换后,需要将server.aof_fd重置为新打开的临时文件的描述符,并手动关闭旧的aof文件描述符。同样由于除了主进程,可能没有别的文件再占用它,所以也会触发系统的unlink操作,从而阻塞主进程
为了解决上述两种场景,主进程在aof功能被关闭时,再次打开旧的文件,持有它的文件描述符。将1和2等价到一起。最后通过异步线程池的方式来主动关闭旧的aof文件。