
只要redo log和binlog保证持久化到磁盘,就能保证MySQL异常重启后,数据可以恢复。而讨论MySQL数据丢失应该从InnoDB事务数据丢失和数据库复制导致数据丢失两方面讨论。
何为丢数据
一般我们希望把一系列的数据作为一个原子操作,这样的话,这一系列操作,要么提交,要么全部回滚掉。当我们提交一个事务,数据库要么告诉我们事务提交成功了,要么告诉我们提交失败。
数据库为了效率等原因,数据只保存在内存中,没有真正的写入到磁盘上去(WAL)。如果数据库响应为“提交成功”,但是由于数据库挂掉,操作系统,数据库主机等任何问题导致这次“提交成功”的事务对数据库的修改没有生效,那么我们认为这个事务的数据丢失了。这个对银行或者支付宝这种业务场景来说是不能接受的。所以,保证数据不丢失也是数据库选择的一个重要衡量指标。
InnoDB事务数据丢失
InnoDB和Oracle都是利用redo 来保证数据一致性的。如果你有从数据库新建一直到数据库挂掉的所有redo,那么你可以将数据完完整整的重新build出来。但是这样的话,速度肯定很慢。所以一般每隔一段时间,数据库会做一个checkpoint的操作,做checkpoint的目的就是为了让在该时刻之前的所有数据都”落地”。这样的话,数据库挂了,内存中的数据丢了,不用从最原始的位置开始恢复,而只需要从最新的checkpoint来恢复。将已经提交的所有事务变更到具体的数据块中,将那些未提交的事务回滚掉。
因此,保证事务的redo日志刷到磁盘就成了事务数据是否丢失的关键。
而InnoDB为了保证日志的刷写的高效,使用了内存的log buffer,另外,由于InnoDB大部分情况下使用的是文件系统,(linux文件系统本身也是有buffer的)而不是直接使用物理块设备,这样的话就有两种丢失日志的可能性:日志保存在log_buffer中,机器挂了,对应的事务数据就丢失了;日志从log buffer刷到了linux文件系统的buffer,机器挂掉了,对应的事务数据就丢失了。当然,文件系统的缓存刷新到硬件设备,还有可能被raid卡的缓存,甚至是磁盘本身的缓存保留,而不是真正的写到磁盘介质上去了。
redolog 写入机制
redo log 三种状态:
- 存在redo log buffer中,物理上在MySQL进程内存中;
- 写到磁盘write, 但是没有持久化fsync,物理上是在文件系统的page cache里面;
- 持久化到磁盘,对应的是hard disk.
日志写到 redo log buffer 是很快的,wirte 到 page cache 也差不多,但是持久化到磁盘的速度就慢多了。
InnoDB 有一个后台线程,每隔 1 秒,就会把 redo log buffer 中的日志,调用 write 写到文件系统的 page cache,然后调用 fsync 持久化到磁盘。
为了控制 redo log 的写入策略,InnoDB 提供了 innodb_flush_log_at_trx_commit 参数,控制redo log 的刷新。它有三种可能取值:
- 1.设置为 0 的时候,表示每次事务提交时都只是把 redo log 留在 redo log buffer 中 ; 这样可能丢失1s的事务数据。
- 2.设置为 1 的时候,表示每次事务提交时都将 redo log 直接持久化到磁盘;这样的话,数据库对IO的要求非常高,如果底层硬件提供的IOPS比较差,MySQL数据库 并发很快就会由于硬件IO的问题而无法提升。(当然,InnoDB的组提交方法为降低IOPS做了很大优化)
- 3.设置为 2 的时候,表示每次事务提交时都只是把 redo log 写到 page cache。如果只是MySQL数据库挂掉了,由于文件系统没有问题,那么对应的事务数据并没有丢失。只有在数据库所在的主机操作系统损坏或者突然掉电的情况下,数据库的事务数据可能丢失1秒之类的事务数据。这样的好处就是,减少了事务数据丢失的概率,而对底层硬件的IO要求也没有那么高(log buffer写到文件系统中,一般只是从log buffer的内存转移的文件系统的内存缓存中,对底层IO没有压力)
注意,事务执行中间过程的 redo log 也是直接写在 redo log buffer 中的,这些 redo log 也会被后台线程一起持久化到磁盘。也就是说,一个没有提交的事务的 redo log,也是可能已经持久化到磁盘的。
组提交
MySQL是如何保证在频繁刷redo log到磁盘情况的同时保证较高的TPS的? – 一次刷一组 - 组提交。
LSN
LSN:log sequence number日志逻辑序列号。LSN是单调递增的,用来对应redo log的一个个写入点。 每次写入长度为length的redo log, LSN的值就会加上length。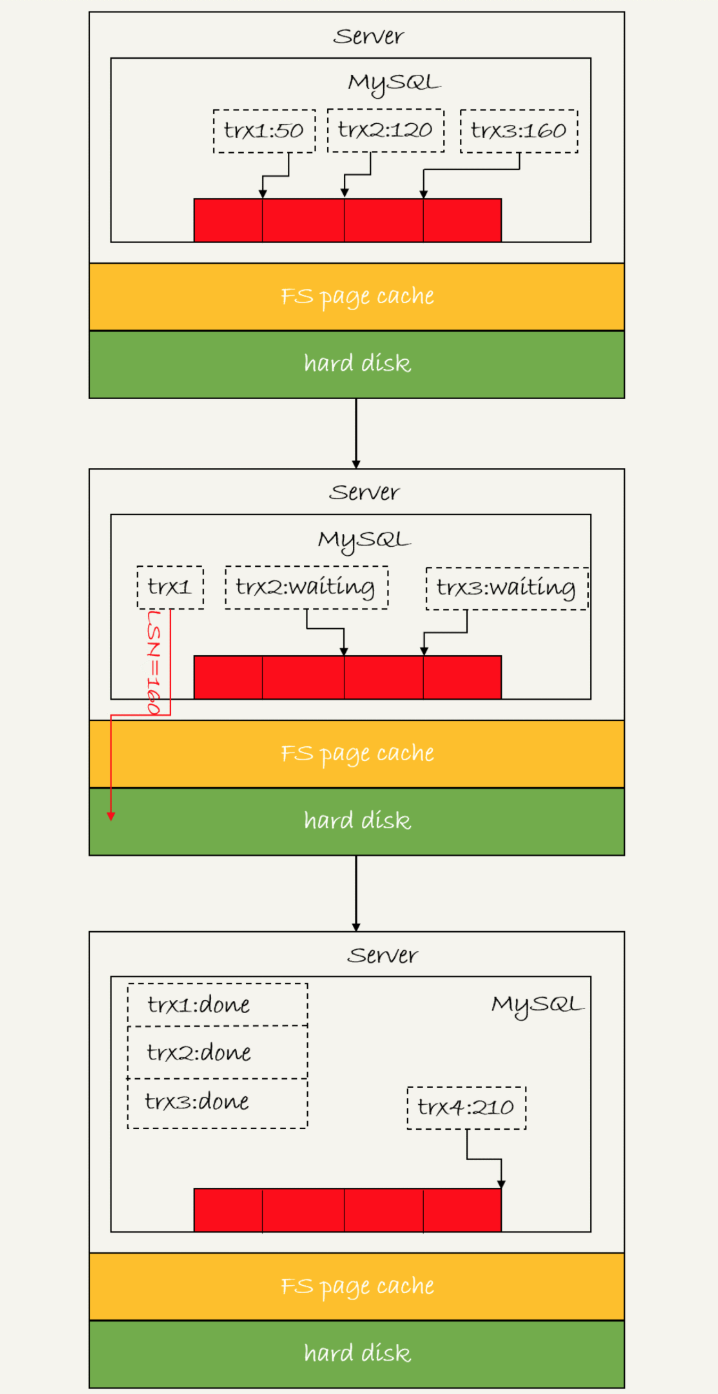
- 第一个到达的事务会被选为这组的leader;
- 等 trx1 要开始写盘的时候,这个组里面已经有了三个事务,这时候 LSN 也变成了 160;
- trx1 去写盘的时候,带的就是 LSN=160,因此等 trx1 返回时,所有 LSN 小于等于 160 的 redo log,都已经被持久化到磁盘;
- 这时候 trx2 和 trx3 就可以直接返回了。
注意,这里“组”的划分为在MySQL进程内存的所有事务组成一组。在并发更新场景下,第一个事务写完redo log buffer以后,接下来fsync 越晚调用,组员可能越多,节约IOPS的效果就越好。
为了让fsync带的组员更多,MySQL的优化:拖时间。
两阶段提交的实际图为:
MySQL为了让组提交的效果更好,把redo log做fsync的时间拖到了步骤1后,这样binlog也可以组提交了,这样可以减少IOPS的消耗。
数据库复制导致数据丢失
MySQL提供异步的数据同步机制。利用这种复制同步机制,当数据库主库无法提供服务时,应用可以快速切换到跟它保持同步的一个备库中去。备库继续为应用提供服务,从而不影响应用的可用性。这里有一个关键的问题,就是应用切换到备库访问,备库的数据需要跟主库的数据一致才能保证不丢失数据。由于目前MySQL还没有提供全同步的主备复制解决方案所以这里也是可能存在数据丢失的情况。
目前MySQL提供两种主备同步的方式:异步(asynchronous)和半同步(Semi-sync)。
异步的方式下,几个线程都是独立的,相互不依赖。而在半同步的情况下,主库的事务提交需要保证至少有一个备库的IO线程已经拉到了数据,这样保证了至少有一个备库有最新的事务数据,避免了数据丢失。这里称为半同步,是因为主库并不要求SQL线程已经执行完成了这个事务。
半同步在MySQL 5.5才开始提供,并且可能引起并发和效率的一系列问题,比如只有一个备库,备库挂掉了,那么主库在事务提交10秒(rpl_semi_sync_master_timeout控制)后,才会继续,之后变成传统的异步方式。所以目前在生产环境下使用半同步的比较少。
在异步方式下,如何保证数据尽量不丢失就成了主要问题。这个问题其实就是如何保证数据库的binlog不丢失,尽快将binlog落地,这样就算数据库挂掉了,我们还可以通过binlog来将丢失的部分数据手工同步到备库上去(MHA会自动抽取缺失的部分补全备库)。
MySQL提供一个sync_binlog参数来控制数据库的binlog刷到磁盘上去。虽然binlog也有binlog cache,但是MySQL并没有控制binlog cache同步到文件系统缓存的相关考虑。所以我们这里不涉及binlog cache。所以很多MySQL DBA设置的sync_binlog并不是最安全的1,而是100或者是0。这样牺牲一定的一致性,可以获得更高的并发和性能。
InnoDB与MySQL协同
根据上面section 2和section 3可知,redo log和binlog都影响数据丢失。但是他们分别在InnoDB和MySQL server层维护。由于一个事务可能使用两种事务引擎,所以MySQL用两段式事务提交来协调事务提交。
两阶段提交
2PC即Innodb对于事务的两阶段提交机制。当MySQL开启binlog的时候,会存在一个内部XA的问题:事务在存储引擎层(redo log)commit的顺序和在binlog中提交的顺序不一致的问题。如果不使用两阶段提交,那么数据库的状态有可能用它的日志恢复出来的库的状态不一致。
事务的commit分为prepare和commit两个阶段:
1、prepare阶段:redo持久化到磁盘(redo group commit),并将回滚段置为prepared状态,此时binlog不做操作。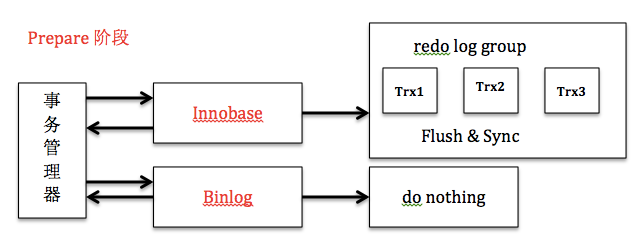
2、commit阶段:innodb释放锁,释放回滚段,设置提交状态,binlog持久化到磁盘,然后存储引擎层提交。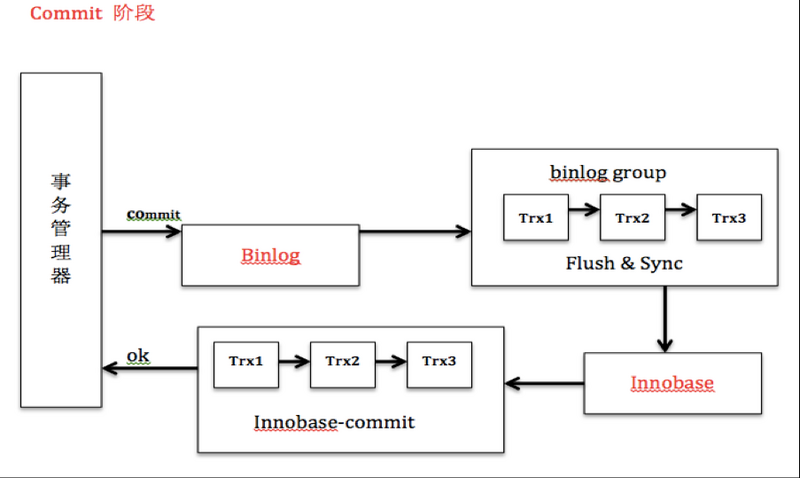
崩溃恢复
一条更新语句的2PC流程图如下:
崩溃恢复目标
避免binlog 主备库恢复数据不一致;避免binlog恢复出来的数据与redolog恢复出来的数据不一致。
崩溃恢复时的判断原则
- 如果redo log里面的事务是完整的,也就是已经有了commit标识,则直接提交;
- 如果redo log里面的事务只有完整的prepare,则判断对应的事务binlog是否存在并完整:
a.如果是,则提交事务;
b.否则,回滚事务。
时刻A:写入redo log处于prepare阶段之后,写binlong之前,放生了crash. 由于此时binlog还没写,redo log 也还没提交,所以崩溃恢复的时候,事务会回滚。这时候binlog还没写,所以也不会传到备库。
时刻B:对应原则2a。
MySQL引入了binlog-checksum参数用来验证binlog的正确性以此验证事务binlog的正确性。而redo log 和 binlog 的数据格式有一个共同的数据字段 - XID。 崩溃恢复的时候,会按顺序扫描redo log:
- 如果碰到既有prepare, 又有commit的redo log,就直接提交;
- 如果碰到只有prepare,而没有commit的redo log, 就拿着这个redo log的XID 去binlog 找对应的事务。以此关联起redo log和binlog。
两阶段提交是经典 的分布式系统问题。举例来说,对于InnoDB引擎,如果redo log提交完了,事务就不能回滚。而如果redo log直接提交,然后binlog 写入失败,则InnoDB又回滚不了,数据和binlog日志又不一致了,因为存在binlog和redo log两种日志且存在主从环境,就需要两阶段提交。两阶段提交就是为了给所有人一个机会,当每个人都说“我OK”的时候,再一起提交。
那如果只用binlog做崩溃恢复,避免费事的两阶段提交可以吗?
答案是binlog是不能做崩溃恢复的。原因1 - binlog 没有能力恢复“数据页”。如下图因为binlog 只记录了逻辑操作,而非像redo log记录数据页磁盘的数据变更。当mysql crash时候,例如binlog1 记录的事件,如果没有WAL 刷盘,binlog是会丢数据的。也就是binlog没有能力恢复数据页。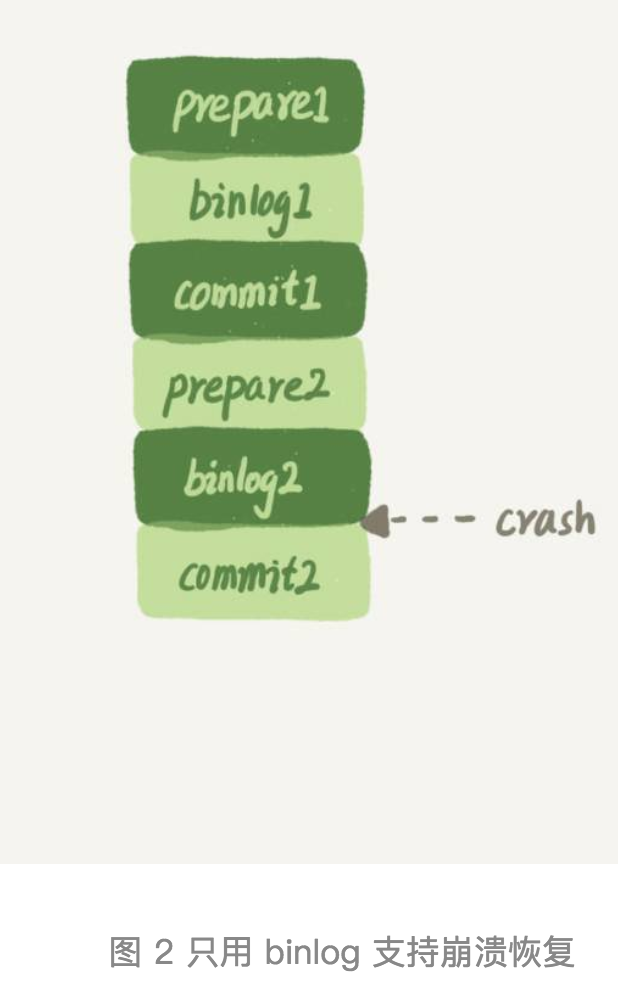
但是binlog 也有自己的特殊用途,不能完全取消:
- 归档。redo log 是循环写,这样历史日志没法保留,redo log无法起到归档的作用。
- 复制。MySQL高可用的基础,就是binlog复制。还有很多公司有异构系统(比如一些数据分析系统),这些系统就靠消费MySQL的binlog 来更新自己的数据。
如何通过redo log做崩溃恢复?
1.如果是正常运行的实例的话,数据页被修改后,跟磁盘的数据页不一致,称为脏页。最终数据罗盘,就是把内存中的数据页写盘,这个过程与redo log无关系。
2.InnoDB如果判断一个数据页可能在崩溃恢复时候丢失了更新,就会将它读到内存,然后让redo log 更新内存内容。更新完成后,内存页变成了脏页,就回到了第一种情况。
binlog 写入机制
binlog写入时机:sql语句或者事务执行完。binlog 写入逻辑比较简单:事务执行过程中,先把日志写到binlog cache, 事务提交的时候,再把binlog cache写到binlog文件中。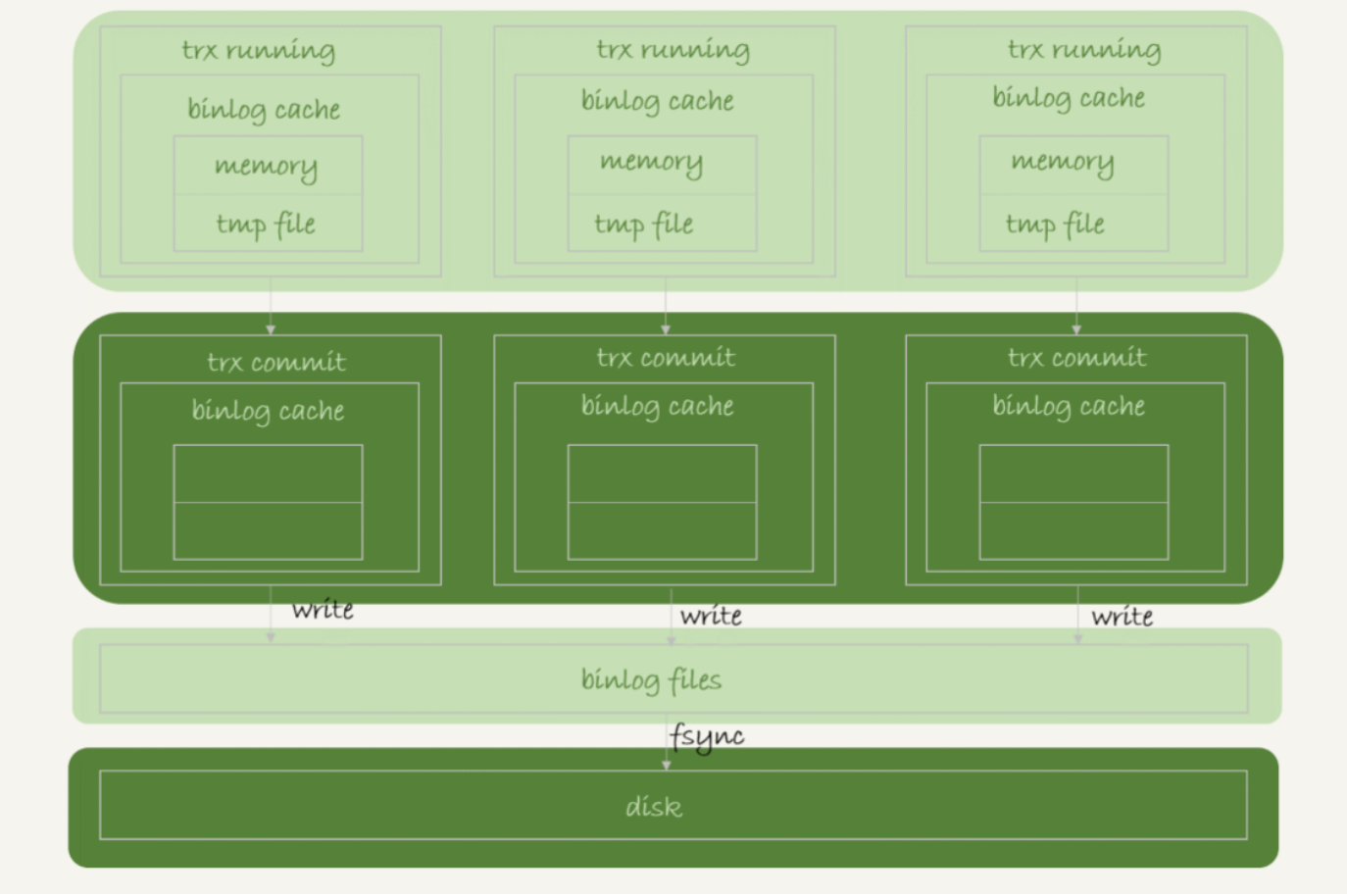
每个线程有自己binlog cache, 但是共用同一份binlog文件。
其中write,指的是把日志写入到文件系统的page cache,并没有把数据持久化到磁盘,所以速度比较快。fsync是将数据持久化到磁盘的操作。一般情况下,fsync才占磁盘IOPS.
write 和 fsync 的时机,是由参数 sync_binlog 控制的:
1.sync_binlog=0 的时候,表示每次提交事务都只 write,不 fsync;
2.sync_binlog=1 的时候,表示每次提交事务都会执行 fsync;
3.sync_binlog=N(N>1) 的时候,表示每次提交事务都 write,但累积 N 个事务后才 fsync。
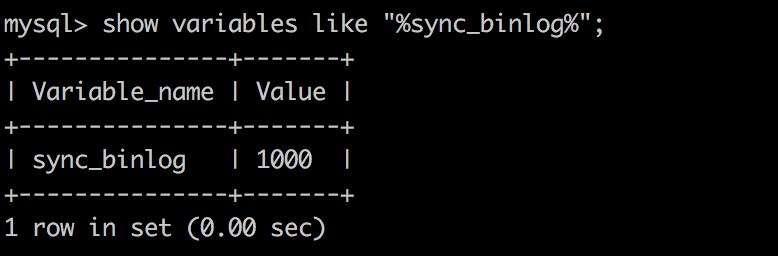
在出现 IO 瓶颈的场景里,将 sync_binlog 设置成一个比较大的值,可以提升性能。在实际的业务场景中,考虑到丢失日志量的可控性,一般不建议将这个参数设成 0,比较常见的是将其设置为 100~1000 中的某个数值。风险是当主机发生异常重启,会丢失最近N个事务的binlog日志。
WAL机制强大的原因
- redo log和binlog都是顺序写,磁盘的顺序写比随机写速度要快;
- 组提交机制,可以大幅度降低磁盘的IOPS消耗。
最后一个问题
如果想避免MySQL出现IO瓶颈,可以怎么做提升性能?
设置 binlog_group_commit_sync_delay 和 binlog_group_commit_sync_no_delay_count 参数,减少 binlog 的写盘次数。这个方法是基于“额外的故意等待”来实现的,因此可能会增加语句的响应时间,但没有丢失数据的风险。
将 sync_binlog 设置为大于 1 的值(比较常见是 100~1000)。这样做的风险是,主机掉电时会丢 binlog 日志。
将 innodb_flush_log_at_trx_commit 设置为 2。这样做的风险是,主机掉电的时候会丢数据。