概述
MySQL每个线程都维护了自己的临时表链表。这样每次session内操作表的时候,先遍历链表,检查是否有该名字的临时表,如果有则优先操作临时表,如果没有再操作普通表。临时表有两种,用户自己创建的-用户临时表以及系统创建的,内部临时表。
临时表特点:
- 一个临时表只能被创建它的session访问,对其他线程不可见;
- 临时表可以与普通表同名;
- session A内有同名的临时表和普通表的时候,show create 语句,以及增删改查语句访问的是临时表;
- show tables命令不显示临时表;
- session结束的时候回自动删除临时表;
用户临时表
由于不用担心线程之间的重名冲突,临时表经常会被用在复杂查询的优化过程中。
1.优化使用场景-分库分表
分区key的选择依据:减少跨库和跨表查询。例如,如果大部分语句都会包含f的等值条件,那么就用f做分区键。这样在proxy这一层解析完SQL语句之后,就嗯嗯更确定这条语句路由到哪个分表做查询。1
select v from ht where f=N;
这时,可以通过分表规则,比如N%1024来确认需要的数据被放到哪个分表上了。1
select v from ht where k>=M order by t_modified desc limit 100;
这时候,由于查询条件里面没有用到分区字段f,只能到所有分区中去查询满足条件的所有行,然后统一做order by操作。操作思路:把各个分库拿到的数据,汇总到一个MySQL实例中的一个表中,然后在这个汇总实例上做逻辑操作。
- 在汇总库创建一个临时表 temp_ht, 表里面包含三个字段 v,k,t_modified;
在各个分库上执行;
1
select v,k,t_modified from ht_x where k>=M order by t_modified desc limit 100;把分库执行的结果插入到temp_ht表中;
- 执行
1
select v from temp_ht order by t_modified desc limit 100;
内部临时表
内部临时表是系统在执行过程中创建的,先用内存临时表,如果内存不够用了,就使用磁盘临时表。tmp_table_size这个配置限制了内存临时表的大小。默认值16M。如果临时表大小超过了tmp_table_size,那么内存临时表就会转成磁盘临时表。当使用磁盘临时表的是,对应的就是一个没有显式索引的InnoDB的排序过程。
MySQL什么时候会使用
- 如果语句执行过程可以一边读数据,一边直接得到结果,是不需要额外内存的,否则就需要额外的内存,来暂存中间结果;
- join_buffer是无序数组,sort_buffer是有序数组,临时表是二位表结构;如果执行逻辑需要二维表特性,就会优先考虑使用临时表。例如union需要用唯一索引约束,group by还需要用到另外一个字段来存累积计数。
1. Union 执行过程
内存临时表起到了暂存数据作用,计算过程用上了临时表主键id的唯一性约束,实现了Union语义。
2. Group by
例如:1
select id%10 as m, count(*) as c from t1 group by m;
1.创建内存临时表,表里有两个字段 m 和 c,主键是 m;
2.扫描表 t1 的索引 a,依次取出叶子节点上的 id 值,计算 id%10 的结果,记为 x;
2.1如果临时表中没有主键为 x 的行,就插入一个记录 (x,1);
2.2如果表中有主键为 x 的行,就将 x 这一行的 c 值加 1;
3.遍历完成后,再根据m排序,将得到的结果集返回给客户端。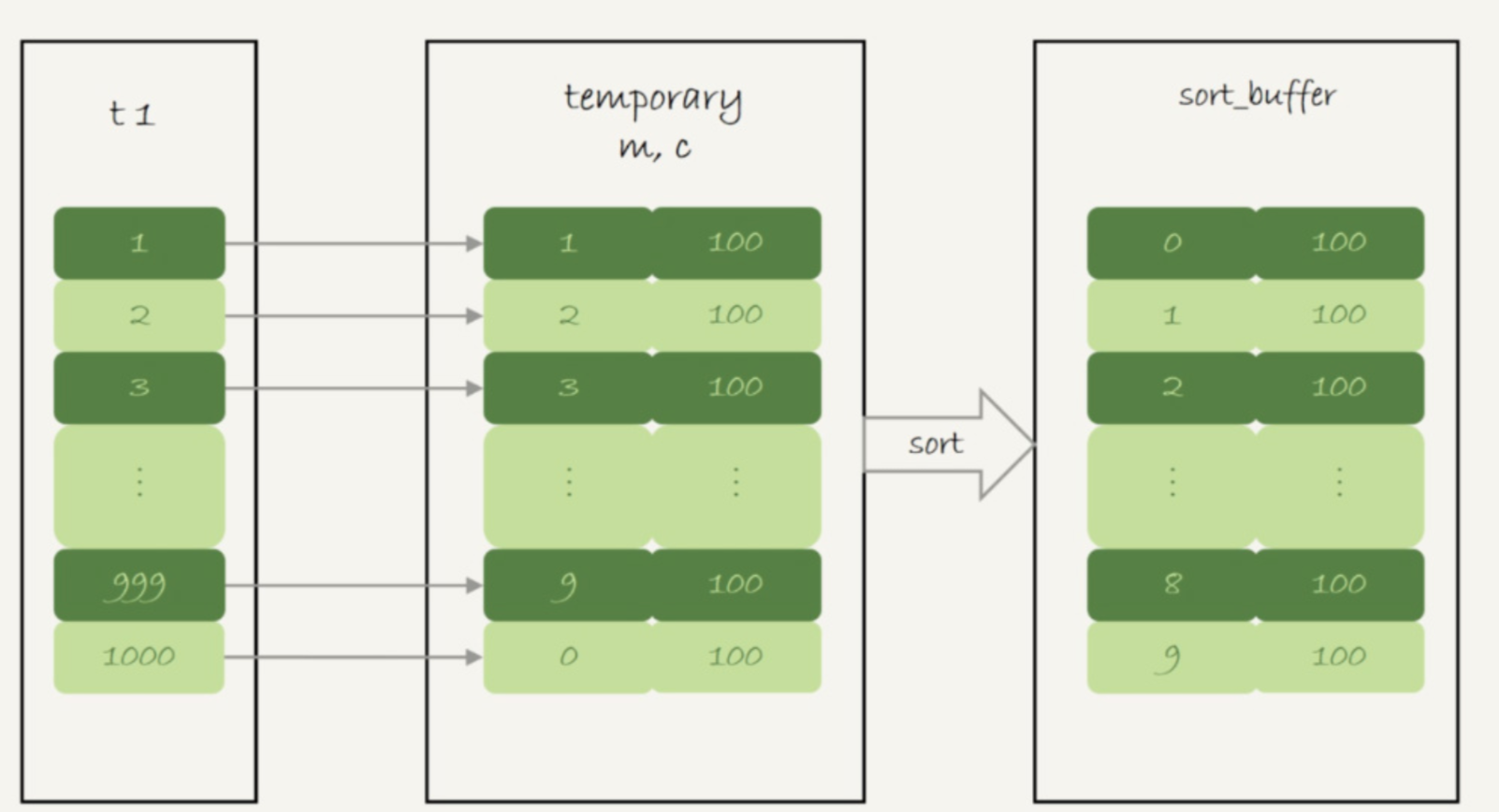
group by的弊端是:如果数据量很大,group by 又用到了临时表,很可能临时内存表不够用,要使用到磁盘临时表,这样性能就很差了。
Group by 优化方法-索引
之所以group by 需要临时表,是因为数据无序(id%10)需要暂存。如果数据都有序,依次+1, 就不需要临时表了。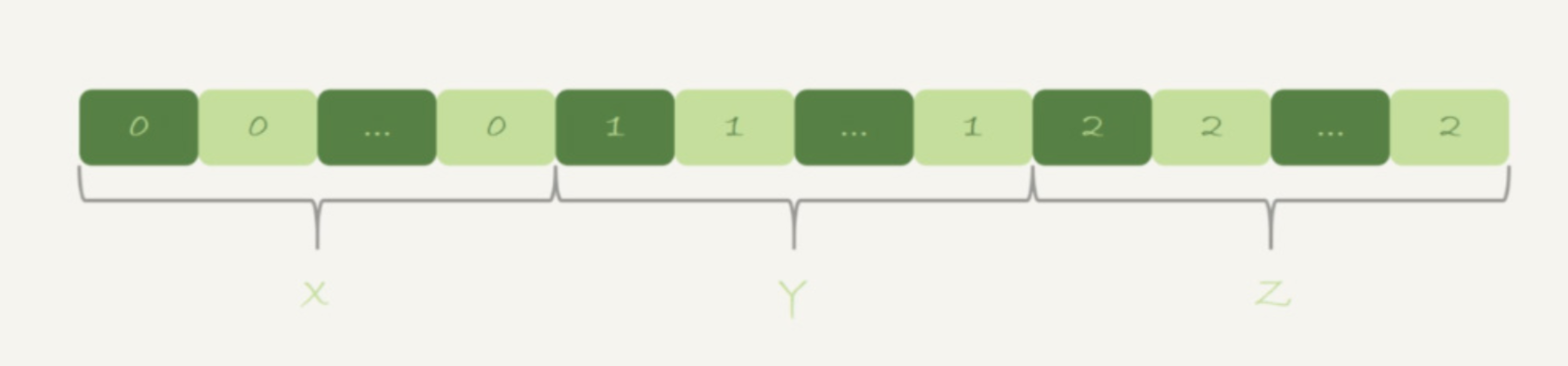
因此解决方法是可以给m%10增加个列,并添加该列索引,保证数据有序。或者:MySQL 5.7的generated column机制,用来实现列数据的关联更新。1
alter table t1 add column z int generated always as(id % 100), add index(z);
group by优化方法 – 直接排序
如果不适合创建索引,就只能直接用磁盘临时表存储优化,避免先存储到内存临时表再转到磁盘临时表。在group by语句中加入SQL_BIG_RESULT提示,告诉优化器直接使用磁盘临时表。1
select SQL_BIG_RESULT id%100 as m, count(*) as c from t1 group by m;
MySQL优化器判断,磁盘临时存储是B+树存储,存储效率不如数组高。因此在数据量大的时候,磁盘临时存储使用数组存。因此执行流程:
- 初始化sort_buffer, 确定放入一个整形字段,记为m;
- 扫描表 t1 的索引 a,依次取出里面的 id 值, 将 id%100 的值存入 sort_buffer 中;
- 扫描完成后,对 sort_buffer 的字段 m 做排序(如果 sort_buffer 内存不够用,就会利用磁盘临时文件辅助排序);
- 排序完成后,就得到了一个有序数组。
根据有序数组,得到数组里面的不同值,以及每个值的出现次数。
3. insert select
1 | insert into t(c,d) (select c+1, d from t force index(c) order by c desc limit 1); |
执行过程:
1、创建临时表,表里有两个字段c,d
2、按照索引c扫描t, 依次取c=4,3,2,1,然后回表,读到c和d的值写入临时表。这时row_examined=4;
3、由于语义里面有 limit 1,所以只取了临时表的第一行,再插入到表 t 中。这时,Rows_examined 的值加 1,变成了 5。
这个语句不好的地方是:这个语句会导致在表 t 上做全表扫描,并且会给索引 c 上的所有间隙都加上共享的 next-key lock。所以,这个语句执行期间,其他事务不能在这个表上插入数据。
使用临时表的原因是这类一边遍历数据,一边更新数据的情况,如果读出来的数据直接写回原表,就有可能在遍历过程中,读到刚刚插入的记录。新插入的记录如果参与计算逻辑,就跟语义不符。
优化办法:先 insert into 到临时表 temp_t,这样就只需要扫描一行;然后再从表 temp_t 里面取出这行数据插入表 t1。1
2
3
4create temporary table temp_t(c int,d int) engine=memory;
insert into temp_t (select c+1, d from t force index(c) order by c desc limit 1);
insert into t select * from temp_t;
drop table temp_t;
