背景
我负责的统一权限系统的管理端首页优化功能上线了一批新功能接口。发现一个接口响应延时比较长(近1s)的接口,接口如下: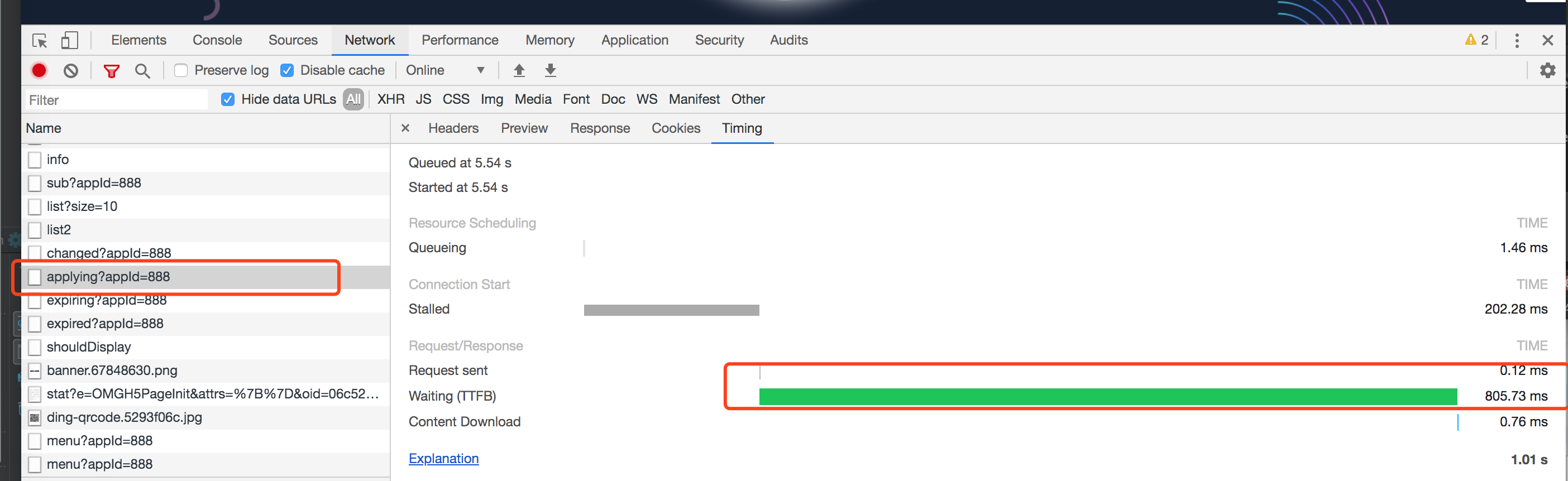
由于接口逻辑层比较简单,只是调service查表的数据逻辑,初步判断是查DB效率太低。通过查看rds慢查询日志得到了验证。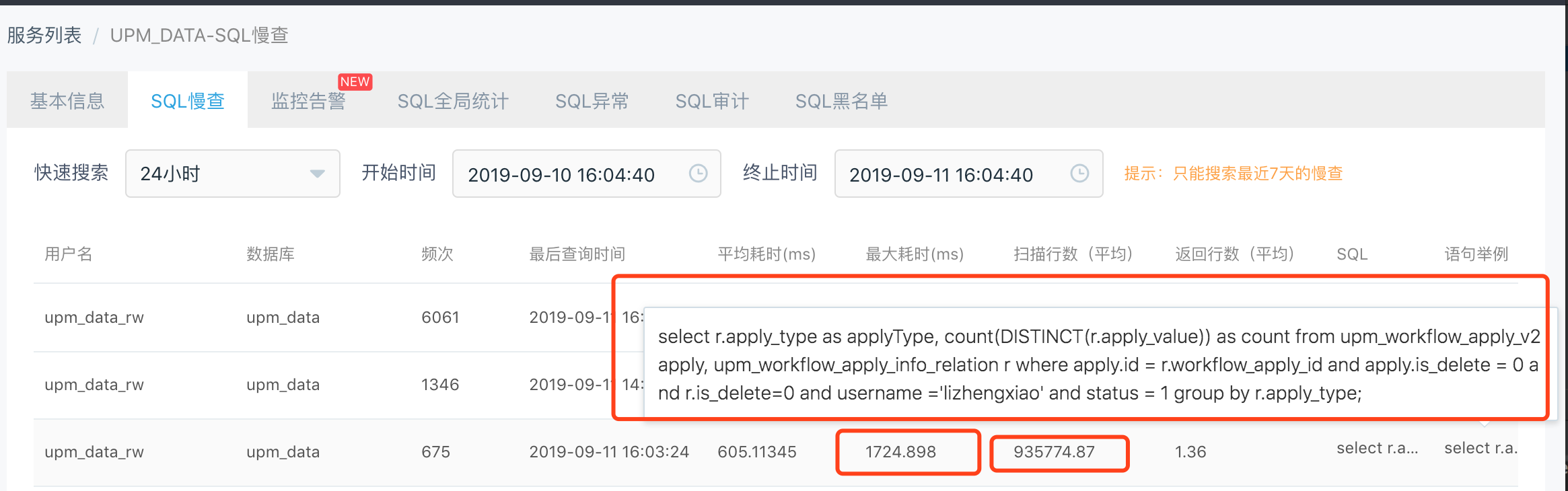
定位到查询的业务SQL ,SQL语句为:1
2
3
4
5
6
7
8
9
10
11
12select
r.apply_type as applyType, count(DISTINCT(r.apply_value)) as count
from
t1 apply,
t2 r
where
apply.id = r.workflow_apply_id
and apply.is_delete = 0
and r.is_delete = 0
and username = "tomcat"
and status = 1
group by r.apply_type
该语句的业务逻辑为返回用户正在申请中的权限类型:权限数列表。其中表t1为权限申请记录表,表t2 为申请记录与申请实体关系表,upm_data.t2表的 is_delete = 0 行数908247。
explain 一下看看: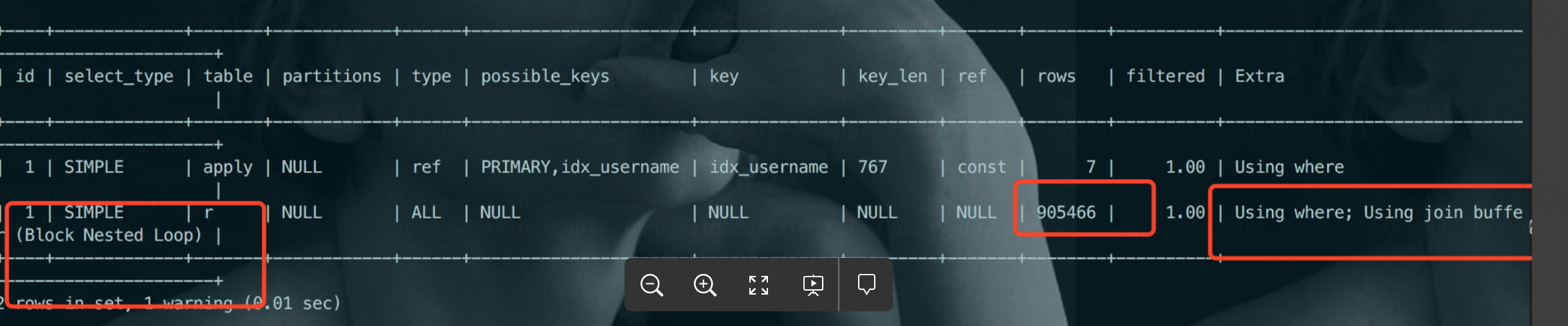
发现出现了影响性能的join - BNL
这里回顾下几种类型的join:1
select * from t1 straight_join t2 on (t1.a=t2.b); //t1 行数N, t2行数M- NLJ (Index Nested-Loop Join)
表t1 join(驱动)表t2。如果可以使用被驱动表的索引,则为NLJ。执行过程类似于嵌套循环。总的扫描行数是N+N*2log2M
- BNL (Block Nested-Loop Join)
表t1 join(驱动)表t2。如果不可以使用被驱动表t2的索引,则每次到t2匹配的时候,都要做一次全表扫描。执行次数为N*M。
BNL 的算法流程:
Situation1: join_buffer放得下
- 把表t1的数据读入线程内存join_buffer中,由于我们这个语句写的是select *, 因此是把整个表t1 放入内存;
- 扫描表t2, 把表t2中的每一行取出来,跟join_buffer中的数据做对比,满足join条件的,作为结果集的一部分返回。
BNL中,表t1和t2都做了一次全表扫描,因此总的扫描行数是N+M。由于join_buffer是以无序数组的方式组织的,因此对于表t2中的每一行,都要做M次判断,总共需要join_buffer内存判断次数是N*M次 (内存操作)。另外BNL选大表做驱动表,还是选小表做驱动表都是一样的。
Situation2: join_buffer放不下
如果放不下t1的所有数据的话,策略很简单,就是分段放。
- 扫描表 t1,顺序读取数据行放入 join_buffer 中,放完第 88 行 join_buffer 满了,继续第 2 步;
- 扫描表 t2,把 t2 中的每一行取出来,跟 join_buffer 中的数据做对比,满足 join 条件的,作为结果集的一部分返回;
- 清空 join_buffer;
- 继续扫描表 t1,顺序读取最后的 12 行数据放入 join_buffer 中,继续执行第 2 步。
内存判断次数是N*M次 , 这种情况选择小表作为驱动表。
总的来说,如果要使用join,要避免出现BNL, 要给被驱动的表的字段加索引。另外,要小表驱动大表(在决定哪个表做驱动表的时候,应该是两个表按照各自的条件过滤,过滤完成之后,计算参与 join 的各个字段的总数据量,数据量小的那个表,就是“小表”,应该作为驱动表。)。
再回看为什么会出现BNL?
被驱动表upm_workflow_apply_info_relation的驱动字段workflow_apply_id 并没有加索引。导致在表被join时候,MySQL使用了BNL算法。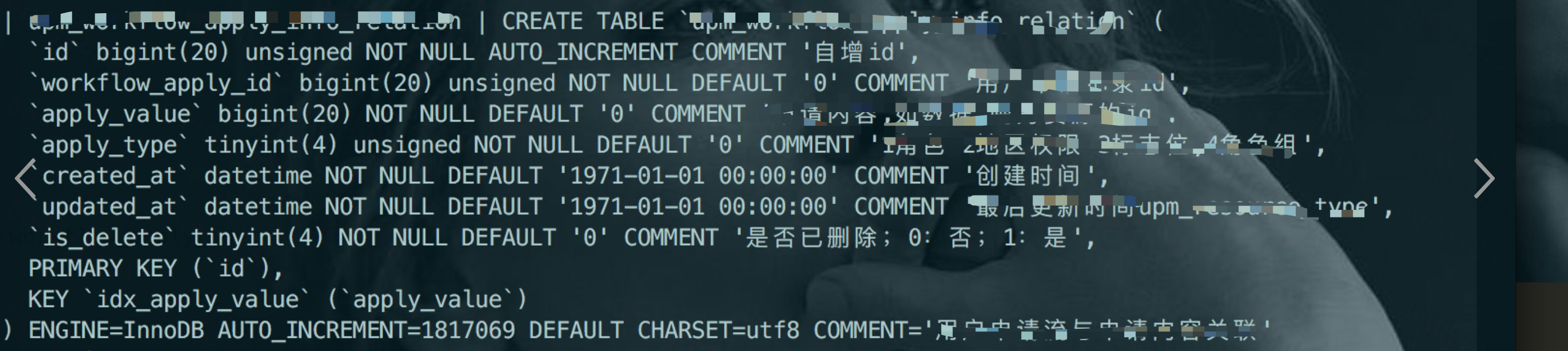
因此优化第一条就是加索引:
另外第二条优化,经同事提醒驱动表upm_workflow_apply_v2的username 字符串的索引查询效率要远低于user_id 的索引效率。因此修改查询语句条件 “username =” 改为 “user_id =”1
2
3
4
5
6
7
8
9
10
11
12select
r.apply_type as applyType, count(DISTINCT(r.apply_value)) as count
from
upm_workflow_apply_v2 apply,
upm_workflow_apply_info_relation r
where
apply.id = r.workflow_apply_id
and apply.is_delete = 0
and r.is_delete = 0
and user_id = "123123"
and status = 1
group by r.apply_type
结论
遇到join语句性能瓶颈的时候,explain一下,如果出现了BNL,一定要优化,要给被驱动表加索引。
要小表驱动大表