
题图不相关,图为2019鸟巢五月天演唱会所拍。
本文是笔者将Flink用到公司业务上的一次实践,目的是为了实现实时推荐效果,提升笔者所负责的系统的用户体验。
背景
权限申请服务是滴滴UPM统一权限系统一个重要的用户使用入口。目前,权限申请量已达周10000单, 申请用户周4000人。 随着申请量日益增多,我们发现用户反馈大量集中在:“用户想要要访问xxx页面/想做xxx,要申请UPM权限,但是用户不知道这个xxx页面是UPM的什么业务子系统”,“用户要访问xxx页面,用户虽然知道这是xxx系统的,但是不知道申请什么角色”。
抽象来说,很多用户使用UPM的痛点为不清楚要申请哪一系统的哪个权限。矛盾点在于UPM的定位是公司级统一权限系统(最新数据显示接入UPM系统1000+个,使用UPM鉴权系统近800个)。这种平台定位就会导致用户要先选择业务系统,再选择并申请权限。而用户的核心诉求就是申请权限,然而由于很多用户对业务系统的了解不足, 会出现用户在UPM申请权限难的困境。为了提升用户申请权限的体验,我们做了权限申请实时推荐。
方案
首先调研了近5天鉴权的用户发起申请率。在UPM中,用户,业务系统,UPM三者的关系如下图所示,用户访问业务系统,业务系统会携带用户信息(通常是用户账号)调用UPM鉴权接口到UPM服务端进行鉴权。UPM服务端返回给业务系统鉴权结果,服务端据此做判断,在界面返回给用户是否有权限。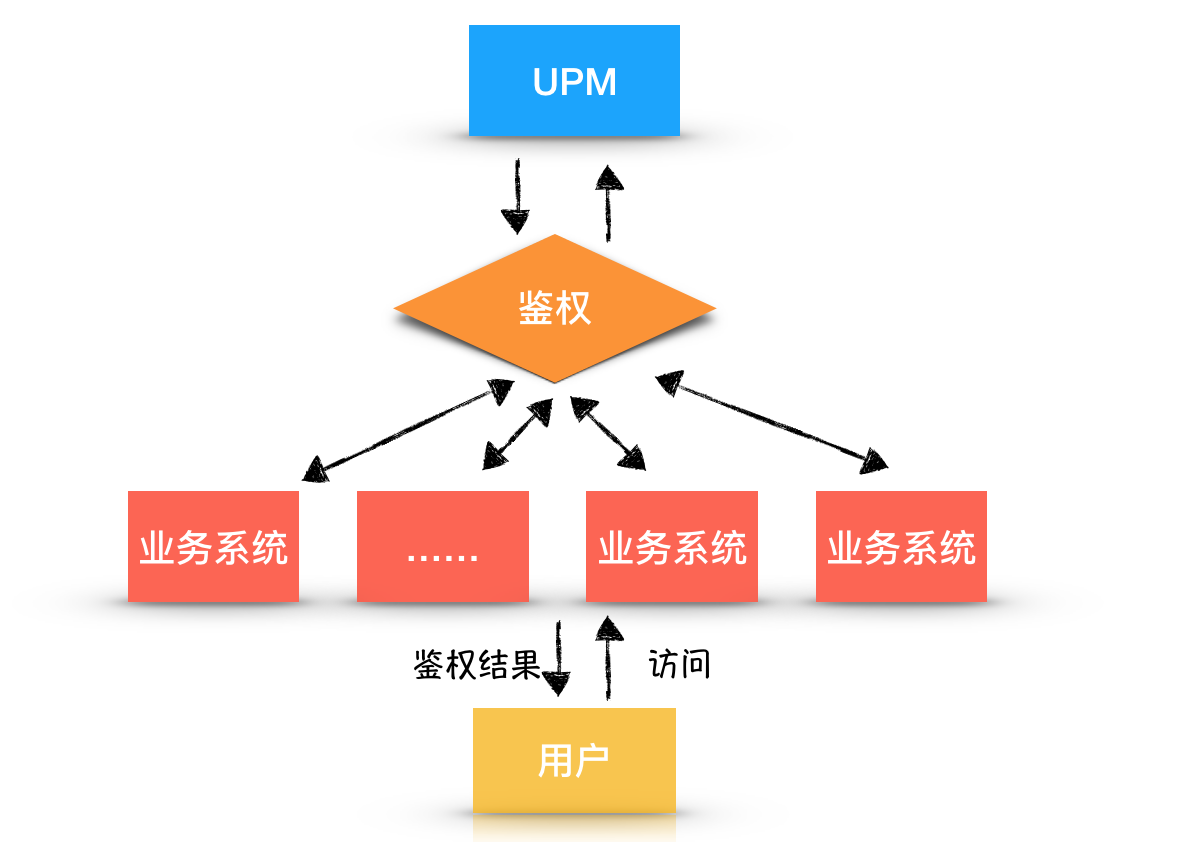
用户从业务系统使用受阻转而到访问UPM的行为路径:用户使用某一业务系统(访问业务系统页面),业务系统判断用户没有权限,推荐来权限系统UPM申请权限。
如果用户真的需要访问这一页面的权限(还有很多用户是误点进来),用户就会到UPM去申请权限。
鉴权的用户发起申请率
鉴权的用户发起申请率 = 发起申请的用户中有过鉴权记录 / 发起申请的用户数
调研发现近5天(10-29~11.3)鉴权的用户发起申请率 为 77.51%。据此判断针对用户在UPM鉴权记录进行权限实时推荐来解决用户申请权限难的痛点是有必要的。
实现
根据用户鉴权日志(UPM鉴权日志 1.2亿 line/天, 120G/天)实现权限实时申请推荐的数据链路如图所示: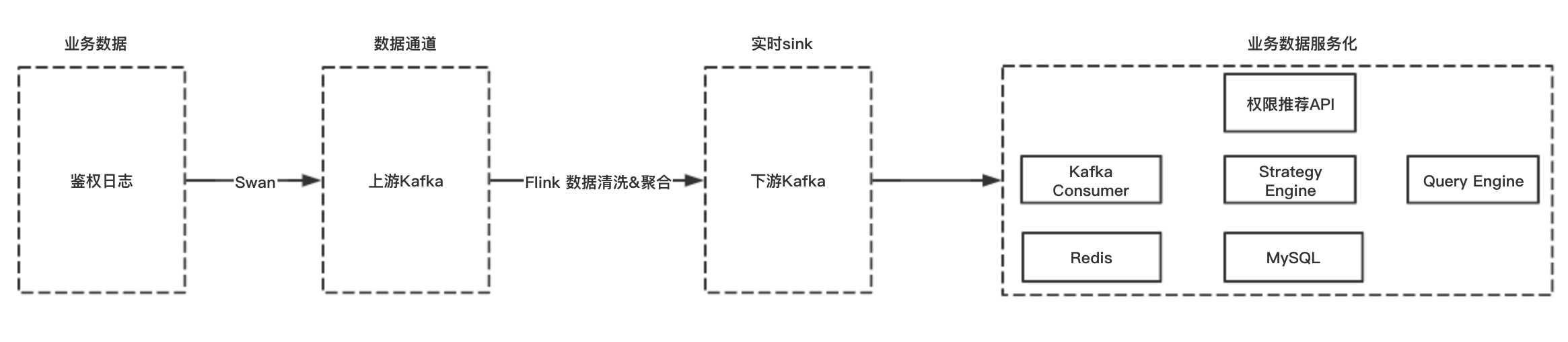
- 业务数据采集:UPM鉴权业务日志采集到Kafka;
- Flink聚合计算:由于申请权限推荐这一场景对于鉴权日志分析到实时性比较高,因此采用Flink流计算对鉴权日志实时处理, 并输出结果到下游Kafka。
- 业务应用部分:根据用户最新鉴权记录,进行下游Kafka消费,并根据业务具体情况制定具体推荐策略,例如只推荐开放申请的app, app推荐黑名单机制(如果有定时调用鉴权接口的系统,会被纳入黑名单不进行推荐。)等等。并将用户的最近鉴权记录格式化存储到MySQL和Redis中。
- 推荐API部分:业务提供接口根据用户名推荐用户要申请权限的系统和权限。
Flink实时计算鉴权日志部分,为避免大量重复鉴权记录对下游kafka造成积压,因此采用了10s的window对鉴权结果记录进行聚合。计算逻辑为以下几点:
- 针对鉴权日志map出每条鉴权日志涉及到到业务系统appId, 鉴权用户的用户名 username,鉴权接口upmAPI, 鉴权时间authenticatedTime等字段;
- filter过滤留下response 鉴权结果日志(除去request部分);
- 针对不同的接口的返回,记录用户鉴权失败与否,作为扩展功能,记录在authenticatedResult字段。鉴权接口分为两类:
- 鉴权返回yes or no 的 /user/check/feature接口 (流量Top1接口)。这类接口根据接口返回结果是否等于false可以直接判断用户鉴权是否失败。
- 第二类是获取用户所有权限后业务方自行逻辑判断的接口。例如 /user/get/roles (流量Top2接口,获取用户所有角色), /user/get/areas(获取用户所有地区), /user/get/flags(获取用户所有flags) 等等。这一类接口由于有业务方自行判断的逻辑,目前认为返回接口为空的时候,为用户鉴权失败。
- 格式化结果数据,sink到下游kafka.
Flink 清洗鉴权日志核心代码如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46DataStream<StreamMessage<UPMCoreLog>> inStream = sourceStream
.flatMap(new UPMFlagMapFunc())
// 只留response
.filter(new UPMFliterFunc())
// watermark
.assignTimestampsAndWatermarks(new AscendingTimestampExtractor<StreamMessage<UPMCoreLog>>() {
@Override
public long extractAscendingTimestamp(StreamMessage<UPMCoreLog> element) {
//鉴权实践作为eventTime时间戳
long timestamp = element.getPyload().getAuthenticatedTime().getTime();
return timestamp;
}
})
// key by {appid+username}
.keyBy(new KeySelector<StreamMessage<UPMCoreLog>, Object>() {
@Override
public String getKey(StreamMessage<UPMCoreLog> streamMessage) throws Exception {
return streamMessage.getPyload().generateIndentifying();
}
})
// tumbling time window每10s统计一次鉴权情况
.window(TumblingEventTimeWindows.of(Time.seconds(10)))
// 聚合结果
.reduce(new ReduceFunction<StreamMessage<UPMCoreLog>>() {
@Override
public StreamMessage<UPMCoreLog> reduce(StreamMessage<UPMCoreLog> upmStreamMessage, StreamMessage<UPMCoreLog> t1) throws Exception {
// 保留一条数据
UPMCoreLog baseline = upmStreamMessage.getPyload();
UPMCoreLog valuein = t1.getPyload();
// 更新鉴权时间新的记录
if (valuein.getAuthenticatedTime().after(baseline.getAuthenticatedTime())) {
return t1;
} else {
return upmStreamMessage;
}
}
});
//sink
DataStream<String> outStream = inStream.map(new MapFunction<StreamMessage<UPMCoreLog>, String>() {
@Override
public String map(StreamMessage<UPMCoreLog> value) throws Exception {
UPMCoreLog pyload = value.getPyload();
return pyload.toString();
}
});
通过Flink对用户的每条鉴权结果进行判断,清洗出格式化的用户鉴权记录存储到下游Kafka,消息记录如下所示:1
2
3
4
5
6
7
8
9
{
"username":"XXX", // 用户
"appId":962, // 业务系统ID
"authenticatedTime":1572770351000,
"upmAPI":"/user/get/roles", // 鉴权接口
"isReq":false,
"authenticatedResult":false // 鉴权是否成功
}
有了下游Kafka存储用户鉴权结果的格式化记录后,就可以实时消费用户鉴权结果消息,将用户最新被拦截无权限的业务系统信息存储到Redis/MySQL 中,以此做权限申请推荐。
产品效果: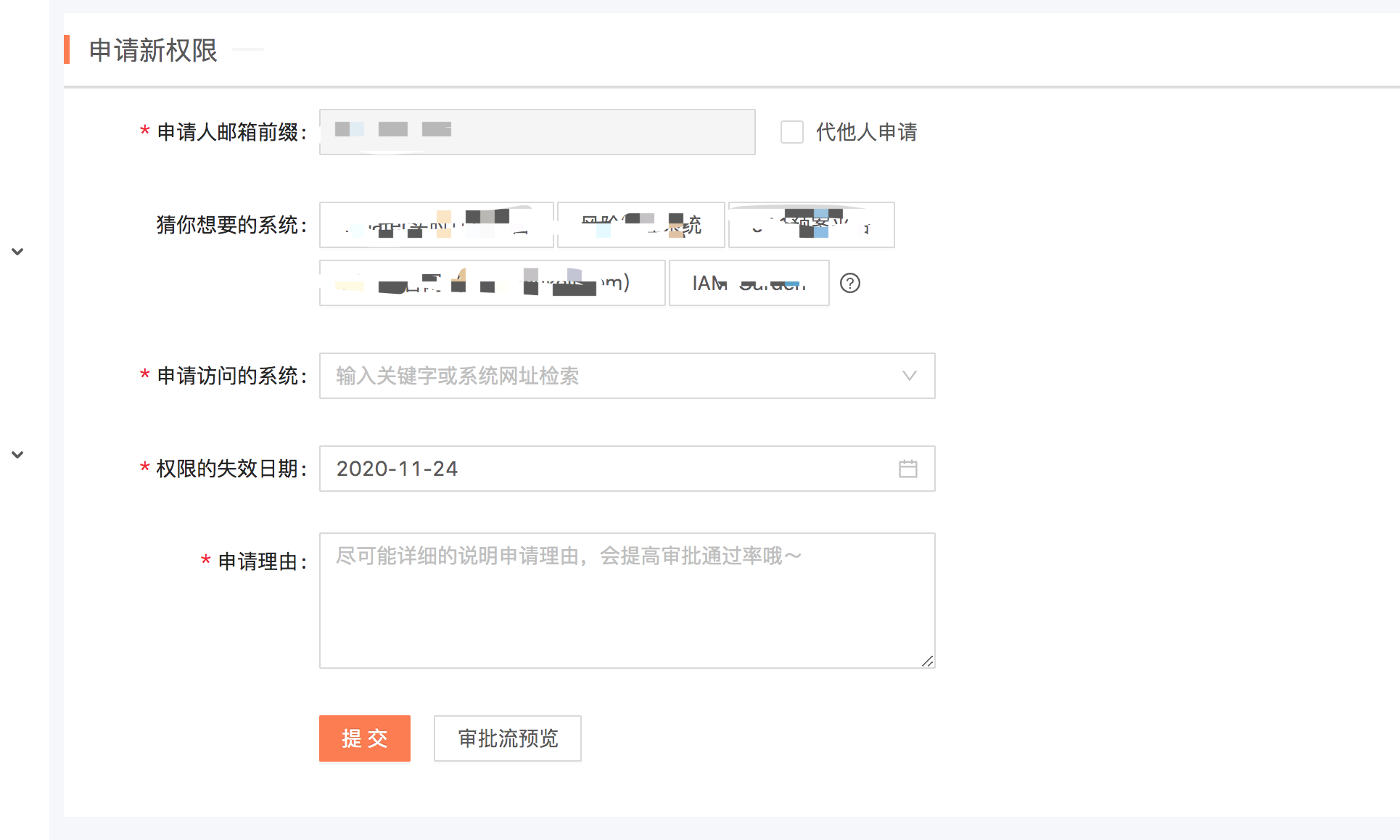
难点&接下来工作
用户申请权限的实时推荐逻辑是基于用户访问业务系统的的鉴权结果日志进行的,但是由于业务方使用UPM鉴权接口比较多样,有时候会造成推荐结果不准确/难以cover住用户真正想要。例如,有的业务方针对自己业务系统比较多的情况,做了一个类似网关的门户系统,门户系统整合了业务方的所有系统。当用户访问门户系统,门户系统携带用户的身份信息及门户系统管理的所有系统appId, 分别到UPM这里鉴权。这样会导致UPM难以获得用户在某一业务系统的最实时的鉴权记录,从而导致推荐的不准确。
用户申请权限终究是想申请业务系统的角色/标识位/地区等。因此,接下来我们会重点做权限的推荐。权限的推荐难度有以下几点:
根据上文所述,鉴权接口分为两类,鉴权返回yes or no 的 /user/check/feature接口 (流量Top1接口)。这类接口根据接口返回结果是否等于false可以直接判断用户鉴权是否失败。业务可以通过feature失败的记录,为用户推荐关联的角色。但是如果业务方设置关联feature 权限点的角色太多的话,也会造成给用户推荐的角色太多的情况, 这样很可能导致用户更为迷惑。
第二类是获取用户所有权限后业务方自行逻辑判断的接口。例如 /user/get/roles (流量Top2接口,获取用户所有角色), /user/get/areas(获取用户所有地区), /user/get/flags(获取用户所有flags) 等等。这一类接口由于有业务方自行判断的逻辑,目前认为返回接口为空的时候,为用户鉴权失败。这一类接口,UPM服务端是无法猜测用户需要申请的角色。因此使用这类接口的业务方,我们无法做去权限推荐。
- 用户申请权限推荐只根据鉴权记录这一维度是否有些单一,后续还需要调研是否需要结合用户岗位进行推荐。