
本文是RocketMQ源码分析系列之三,如有疑问或者技术探讨,可以email me,欢迎探讨.
设计思路
关键词: CommitLog, ConsumeQueue, 内存映射文件
一个产品的技术选型一般都要基于其使用场景,RocketMQ的数据存储也不例外。在数据存储方面,RocketMQ采用了将数据(所有topic的消息)只写在了一个唯一的文件(CommitLog)里面, 实现顺序写随即读. 之所以这么设计,是有其历史原因的:RocketMQ的最初使用场景是为了支持淘宝双十一实时订单场景, 面临的是大数据量,topic-partition多的场景。另外Rocket在设计上最初借鉴了Kafka并试图克服其在topic-partition增多时候的不足。
先来看看Kafka是怎么做数据存储的。
在Kafka的架构设计上,消息以topic分类,每个topic存储在多个partition上,一个partition对应一个单独的log文件上。消息不断追加到log的末尾(顺序写)。partition可以分布在不同的机器上,因此一个topic的消息可以水平扩展到多机器上。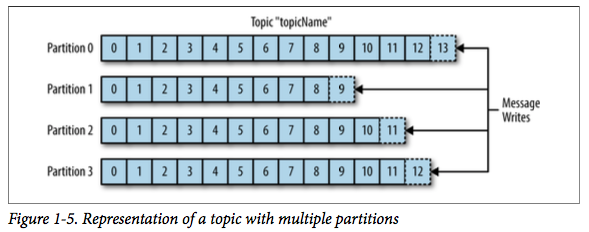
当Producer想要写入消息时候,消息会根据其key的哈希值分派到对应的partition上,然后追加写到partition的log文件。但是从IO层面看,这种多topic-多partition方式,对于每个文件来说虽然是顺序IO,但是当并发读写多个partition,实际上是随机IO读写到多个partition的。由于磁盘是随机读写慢,顺序读写快。因此,实验证明:topic数量增加到一定程度,Kafka性能急剧下降。
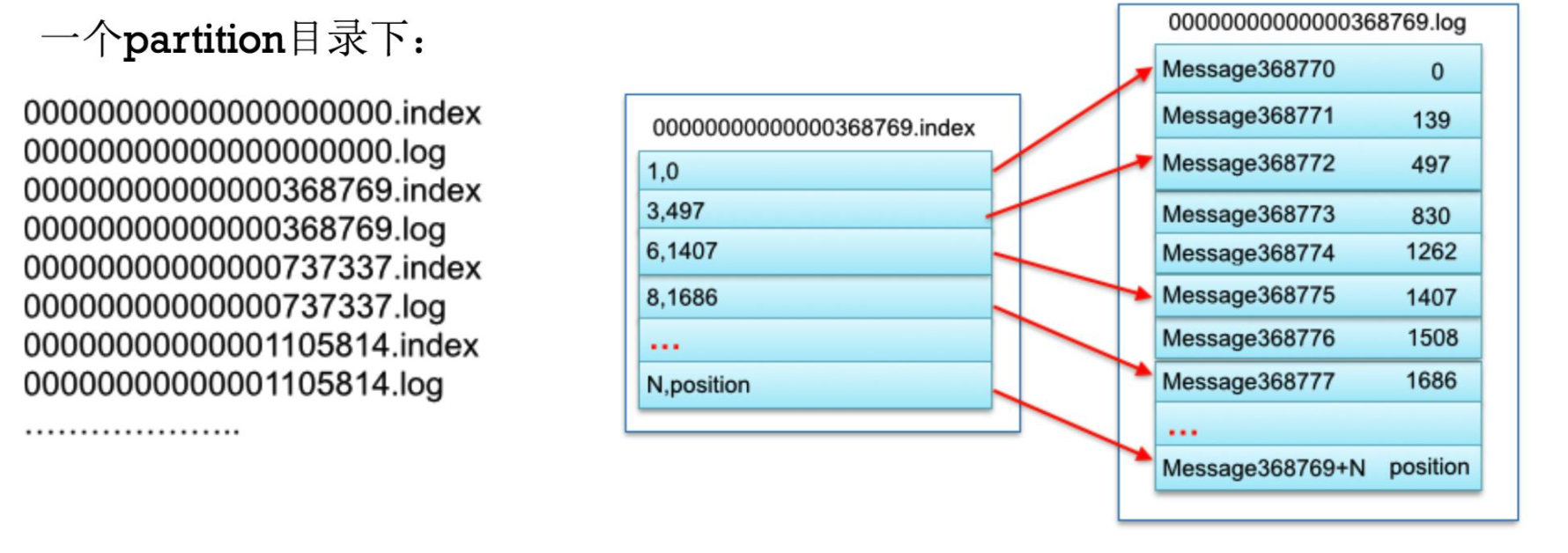
为了解决这个问题,RocketMQ的消息是存储在一个单一的CommitLog文件里,从而避免是磁盘的随机IO。
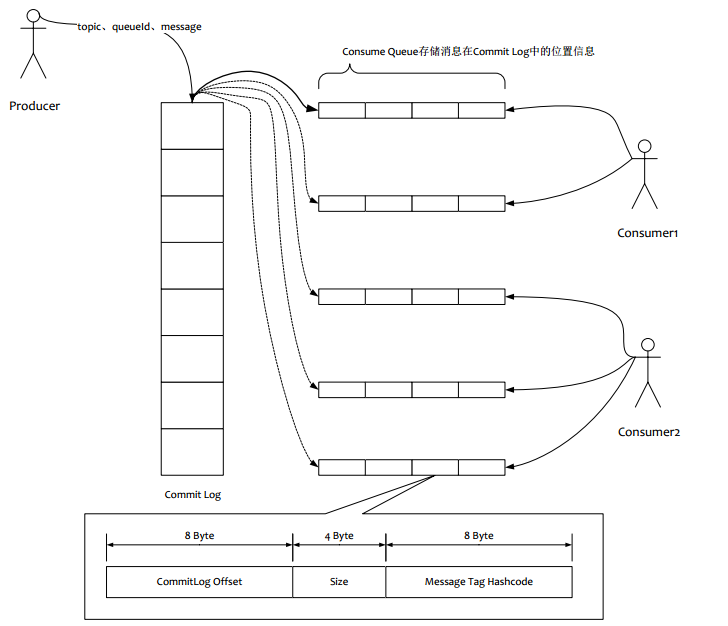
另外Kafka针对Producer和Consumer使用了同1份存储结构,而RocketMQ却为Producer和Consumer分别设计了不同的存储结构,Producer对应CommitLog, Consumer对应ConsumeQueue。RocketMQ把所有消息都存储在一个CommitLog里,然后再根据topic - queueId异步分发给ConsumeQueue。 ConsumeQueue是逻辑队列,并不真正存储消息的内容,仅仅存储消息在CommitLog的位移(offset)。之所以分成多个queue,是因为这样可以让多个消费者同时消费,而不需要上锁。
对于消费者来说,ConsumeQueue其实是CommitLog的一个索引文件。Consumer消费消息的时候,要读2次:
- 先读ConsumeQueue得到offset
- 再根据offset从读CommitLog得到消息。
有关数据存储,可以看出通过将消息都追加写到一个CommitLog文件,实现了顺序写提高了磁盘IO性能。但是这里还有一个问题,Consumer在读消息的时候,实际上是一个随机读磁盘的过程。那么RocketMQ是怎么克服这一点的呢?
- 更多靠的是预读取,就是一次加载了很多数据到内存,被读到的概率也很大。
- 使用零拷贝,提升了消费消息时候从磁盘加载数据到内存的效率。
关于零拷贝:
对于CommitLog和ConsumeQueue源代码中都有一个成员MapedFileQueue – Consumer消费消息过程中使用了零拷贝(mmap+write),mmap是一种内存映射文件的方法,即将一个文件或者其他对象映射到进程的地址空间,实现文件磁盘地址和进程虚拟地址空间中的一段虚拟地址的一一映射关系。实现这样的映射关系后,进程就可以采用指针的方式读写操作这一段内存。而系统会自动回写脏页面到对应的文件磁盘,即完成了对文件的操作而不用调用read,write等系统调用函数。相反,内核空间对区域的修改也直接反应到用户空间,从而实现不同进程间的文件共享。有关零拷贝推荐此文。
( 0拷贝的作用就是减少到用户内存的一次拷贝,这里从磁盘加载到一块mmap的内存上,用户程序就可以直接操作了。从用户的角度来看 就是操作这块内存。操作磁盘 底层原理是mmap,也就是0拷贝。)
RocketMQ 采用了 mmap+write 方式实现的零拷贝。通过使用零拷贝,提升了消费消息时候从磁盘加载数据到内存的效率。
Store模块数据核心文件
RocketMQ的数据存储功能在源码中为Store模块,其结构如下图所示: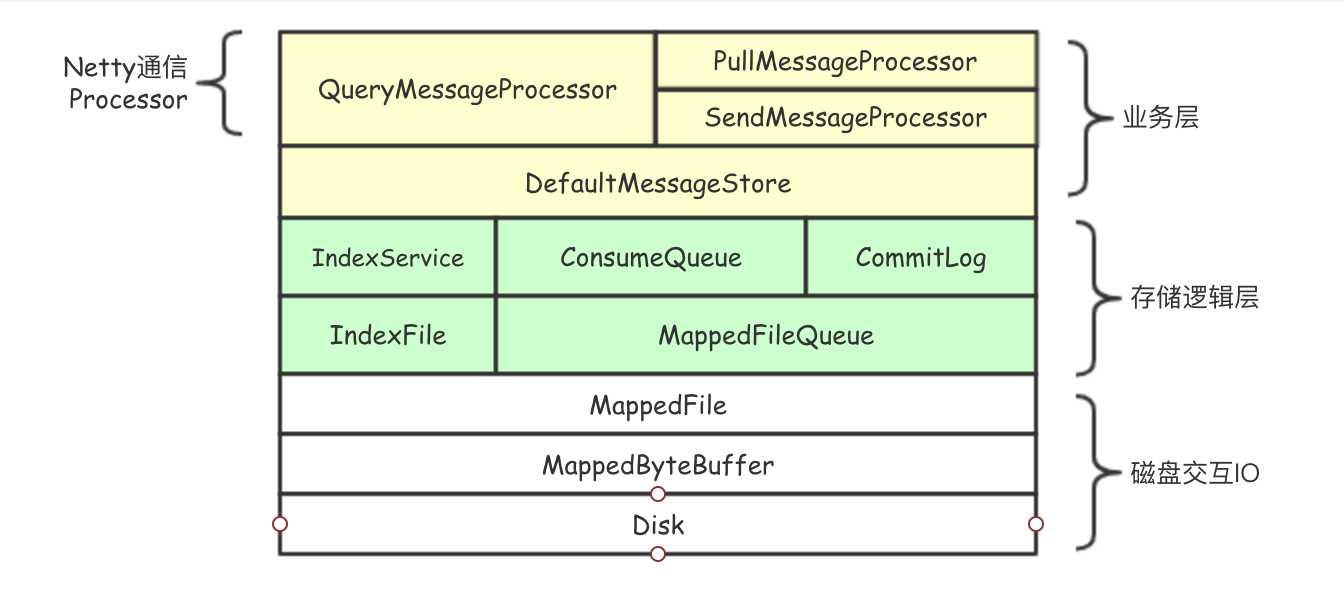
业务层均通过DefaultMessageStore类提供的方法作为统一入口访问底层文件。RocketMQ存储核心围绕以下六类文件:
- IndexFile: 由IndexService类提供服务
- Consumequeue: 文件由Consumequeue类提供服务
- Commitlog: 文件由CommitLog类提供服务
- Checkpoint文件: 由StoreCheckPoint类提供访问服务。Checkpoint文件存储Commitlog,CQ 和Index file的刷盘时间。
- Config文件: 由ConfigMananger类提供访问服务,json格式存储相关配置。
- Lock文件
对于IndexFile/Consumequeue/Commitlog这三类大文件,为了提供读写性能,底层采用java.nio.MappedByteBuffer类,该类是文件内存映射方案(零拷贝),支持随机读/顺序写操作。大文件在存储时候会被分成固定大小的小文件,每个小文件均由MapedFile类提供操作服务;MapedFile类提供了顺序写、随机读、内存数据刷盘、内存清理等与文件相关的服务。MappedFileQueue中用集合list把这些MappedFile文件组成了一个逻辑上连续的队列,从而实现了整个大文件的串联。
MappedFile
MappedFileQueue + Maped File 保存存放在物理机器上的文件信息。
Mapped File: 存储具体的文件信息: 包括文件路径,文件名(文件起始偏移),写位移,读位移等等信息,同时使用了虚拟内存提高IO效率。
MappedFile提供API:1
2
3
4
5public appendMessage(final byte[] data) // 顺序写msg到MapedFile
public commit(final int commitLeastPages)//将内存消息刷盘
public SelectMappedBufferResult selectMappedBuffer(int pos, int size) // 随机读消息
CommitLog
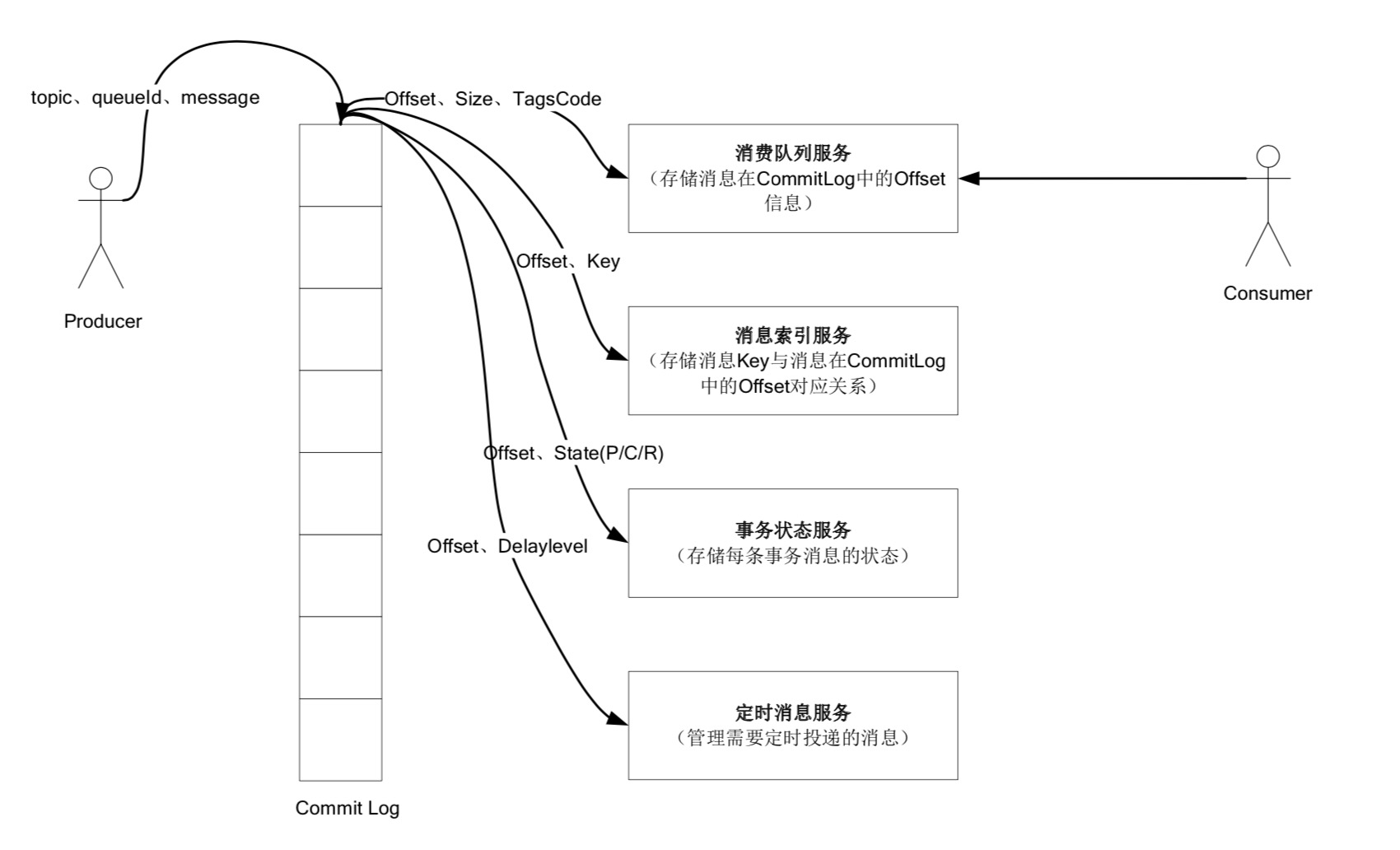
CommitLog是保存消息元数据的物理存储文件,所有到达Broker的消息都会保存到Commitlog文件。这里需要强调的是所有topic的消息都会统一保存在commitLog中,举个例子:当前集群有TopicA, TopicB,这两个Toipc的消息会按照消息到达的先后顺序保存到同一个commitLog中,而不是每个Topic有自己独立的cCommitLog。
每个CommitLog大小上限为1G,满1G之后会自动新建CommitLog文件做保存数据用。
CommitLog的清理机制:
- 按时间清理,默认清理三天前的commitlog文件
- 按磁盘水位清理。当磁盘使用量到达磁盘容量的75%,开始清理最老的commitlog文件。
ConsumeQueue
ConsumeQueue是消息的位置文件,主要存储消息在CommitLog的位置(offset),多个文件构成一个队列。内部采用MappedFileQueue实现了消息位置文件队列功能。1
一个CQ存储单元 = 8字节commitlog offset + 4字节commit log item size + 8字节message tag hashcode.
IndexFile
索引文件存储的消息的索引 - 方便根据topic+消息的key快速查询消息。
具体说来:索引可以理解为一个类似hashtable的结构。建立索引时候根据每条消息的topic + "#" + key的hash值取模计算出实际文件位置absSlotPos,将消息在CommitLog的位移位置存储到slotPos对应的slot里面。1
2
3
4
5
6
7
8
9int absIndexPos = IndexHeader.INDEX_HEADER_SIZE + this.hashSlotNum * hashSlotSize + this.indexHeader.getIndexCount() * indexSize;
// 存入该消息的索引
this.mappedByteBuffer.putInt(absIndexPos, keyHash);
this.mappedByteBuffer.putLong(absIndexPos + 4, phyOffset);
this.mappedByteBuffer.putInt(absIndexPos + 4 + 8, (int) timeDiff);
this.mappedByteBuffer.putInt(absIndexPos + 4 + 8 + 4, slotValue);
this.mappedByteBuffer.putInt(absSlotPos, this.indexHeader.getIndexCount());
ConsumeQueue和IndexFile什么时候建立的呢? – 在Broker启动的时候,会启动一个ReputMessageService线程服务:1
this.reputMessageService.start();
该线程每隔一秒就会执行,根据CommitLog最新追加到的消息不断生成:
- 消息的offset到CommitQueue
- 消息索引到IndexFile
具体流程为: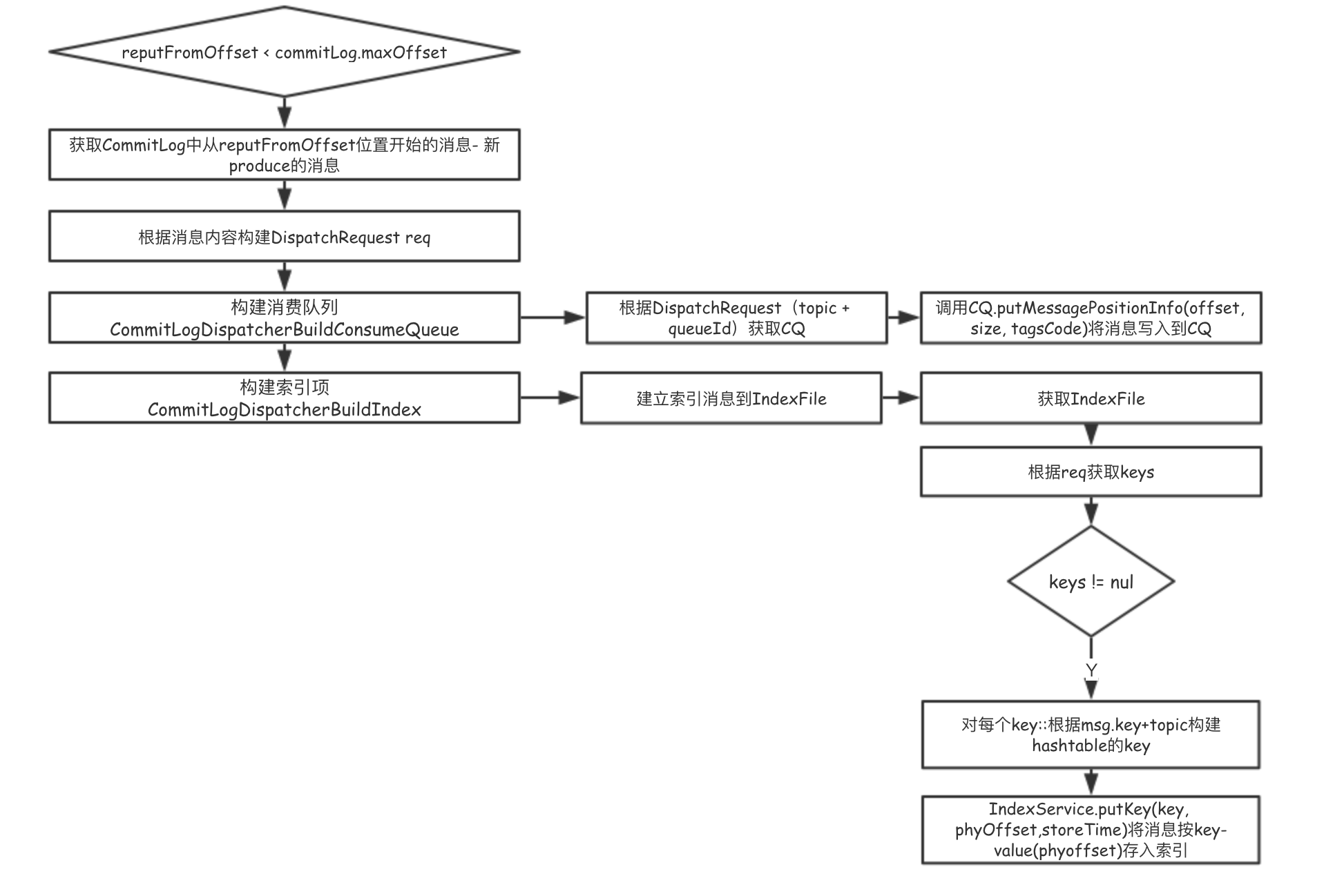
其中:reputOffset: broker启动时候CommitLog的最大offset.
构建ConsumeQueue:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16class CommitLogDispatcherBuildConsumeQueue implements CommitLogDispatcher {
@Override
public void dispatch(DispatchRequest request) {
final int tranType = MessageSysFlag.getTransactionValue(request.getSysFlag());
switch (tranType) {
case MessageSysFlag.TRANSACTION_NOT_TYPE:
case MessageSysFlag.TRANSACTION_COMMIT_TYPE:
DefaultMessageStore.this.putMessagePositionInfo(request);
break;
case MessageSysFlag.TRANSACTION_PREPARED_TYPE:
case MessageSysFlag.TRANSACTION_ROLLBACK_TYPE:
break;
}
}
}
1 | /** |
构建IndexFile:1
2
3
4
5
6
7
8
9class CommitLogDispatcherBuildIndex implements CommitLogDispatcher {
@Override
public void dispatch(DispatchRequest request) {
if (DefaultMessageStore.this.messageStoreConfig.isMessageIndexEnable()) {
DefaultMessageStore.this.indexService.buildIndex(request);
}
}
}
1 | public void buildIndex(DispatchRequest req) { |
数据存储功能
消息队列在使用过程中都会面临着如何承载消息堆积并在合适的时机投递的问题。处理堆积的最佳方式就是数据存储。
消息堆积分为以下两种情况:
- 消息堆积在内存Buffer,一旦超过内存Buffer,可以根据一定的丢弃策略丢弃消息,如CORBA Notification规范中描述。适合能容忍丢弃消息业务,这种情况的堆积能力主要在于内存Buffer大小,而且消息堆积后,性能下降不会太大,因为内存中数据多少对于对外提供的访问能力影响有限。
- 消息堆积持久化存储系统中,例如DB,KV存储,文件记录形式。当消息不能在内存 Cache 命中时,要不可避免的访问磁盘,会产生大量读 IO,读 IO 的吞吐量直接决定了 消息堆积后的访问能力。
RocketMQ的具有亿级消息堆积能力: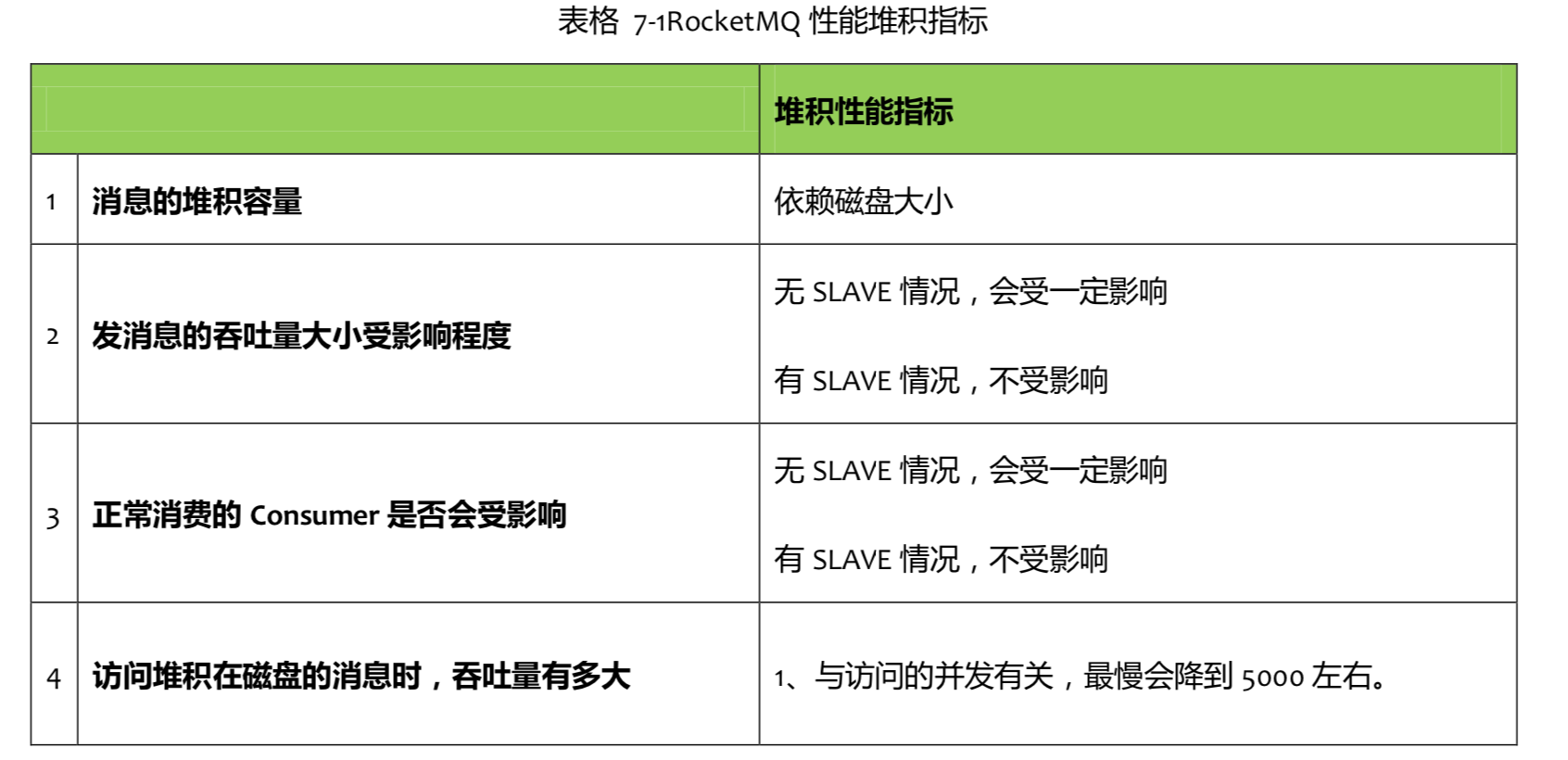
下图是RocketMQ数据的存储管理方式。所有Producer生产的消息,按照插入顺序写入一个CommitLog文件。CommitLog按照固定的大小被切割为多个小文件,每个文件MappedFile都通过内存映射的方式加载入内存。MappedFile随着消息的写入,不断生成,并放在MappedFileQueue队列的最后,每次消息写入都在最后一个MappedFile后追加,直到达到最大的文件大小,重新生成一个新的MappedFile。每个MappedFile名字表示文件中第一条消息在CommitLog中的物理偏移量。每条消息有固定的格式,在写入CommitLog的过程中,RocketMQ会启动一个异步线程,读取MappedFile,根据生产消息时指定的topic和ConsumeQueue id将每条消息在整个CommitLog中的物理偏移量,以及消息的大小和标签码,组织为一条CQUnit,写入对应ConsumeQueue。ConsumeQueue的组织方式与CommitLog类似,每个topic的每个ConsumeQueue独占一个文件夹,文件夹里同样按照MappedFileQueue的方式,组织所有CQStoreUnit。
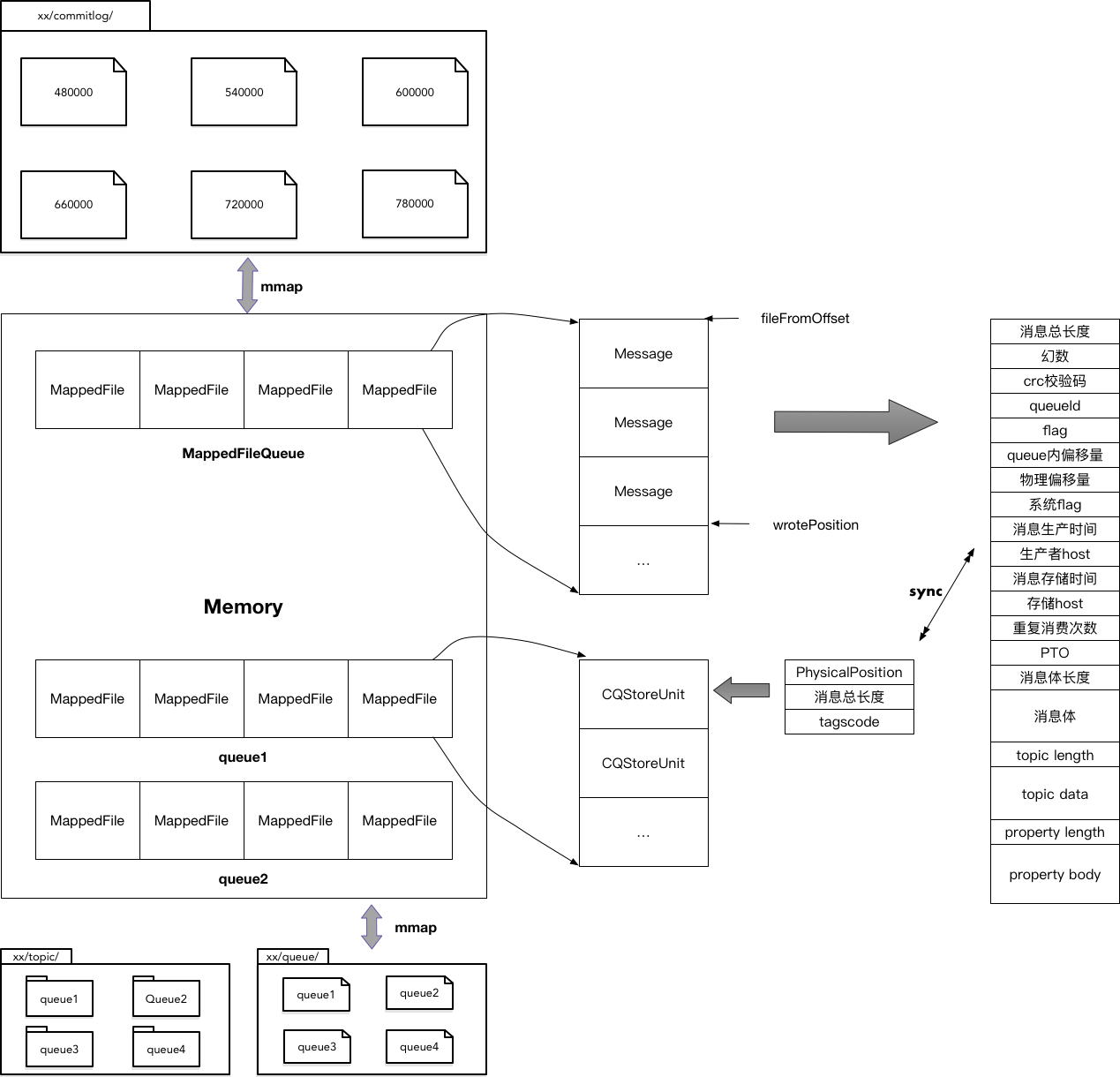
从功能上讲,数据存储用于存储:
- Producer生产的消息
- Consumer的逻辑队列: 记录消息在CommitLog中的offset
- 索引:用于查询消息,当用户想要查询topic下的某个key消息时,能够快速响应.
- 主从复制:用于实现Master - Slave之间的信息同步。
核心类:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30DefaultMessageStore {
private final MessageStoreConfig messageStoreConfig; //存储相关配置,例如存储路径,CommitLog路径及大小
private final CommitLog commitLog;
private final ConcurrentMap<String/* topic */, ConcurrentMap<Integer/* queueId */, ConsumeQueue>> consumeQueueTable; //topic的消费队列表
private final FlushConsumeQueueService flushConsumeQueueService; //CQ刷盘服务线程
private final CleanCommitLogService cleanCommitLogService;//磁盘超过水位进行清理
private final CleanConsumeQueueService cleanConsumeQueueService;
private final IndexService indexService; //索引服务 - 用于创建索引文件集合,当用户想要查询某个topic下某个key的消息时,能够快速响应 主要用于查询消息用的,根据topic+key获取消息,
private final AllocateMappedFileService allocateMappedFileService;
private final ReputMessageService reputMessageService; //CommitLog异步构建CQ和索引文件的服务。
private final HAService haService; //主备同步服务
private final ScheduleMessageService scheduleMessageService;//延迟消息:先把消息投递到delay topic暂存,然后通过定时器把delay topic暂存的消息投递到真实的topic.
private final StoreStatsService storeStatsService; //存储统计服务
private final TransientStorePool transientStorePool;
private final RunningFlags runningFlags = new RunningFlags();
private final SystemClock systemClock = new SystemClock();
private final ScheduledExecutorService scheduledExecutorService =
Executors.newSingleThreadScheduledExecutor(new ThreadFactoryImpl("StoreScheduledThread"));
private final BrokerStatsManager brokerStatsManager; //Broker统计服务
private final MessageArrivingListener messageArrivingListener; //消息到达监听器
private final BrokerConfig brokerConfig;
private volatile boolean shutdown = true;
private StoreCheckpoint storeCheckpoint; //检查点
private AtomicLong printTimes = new AtomicLong(0);
private final LinkedList<CommitLogDispatcher> dispatcherList; //转发CommitLog到CQ
private RandomAccessFile lockFile;
private FileLock lock;
boolean shutDownNormal = false;
} //存储模块核心类,提供数据功能API
Producer生产消息
1 | PutMessageResult result = this.commitLog.putMessage(msg); // 向CommitLog追加消息 |
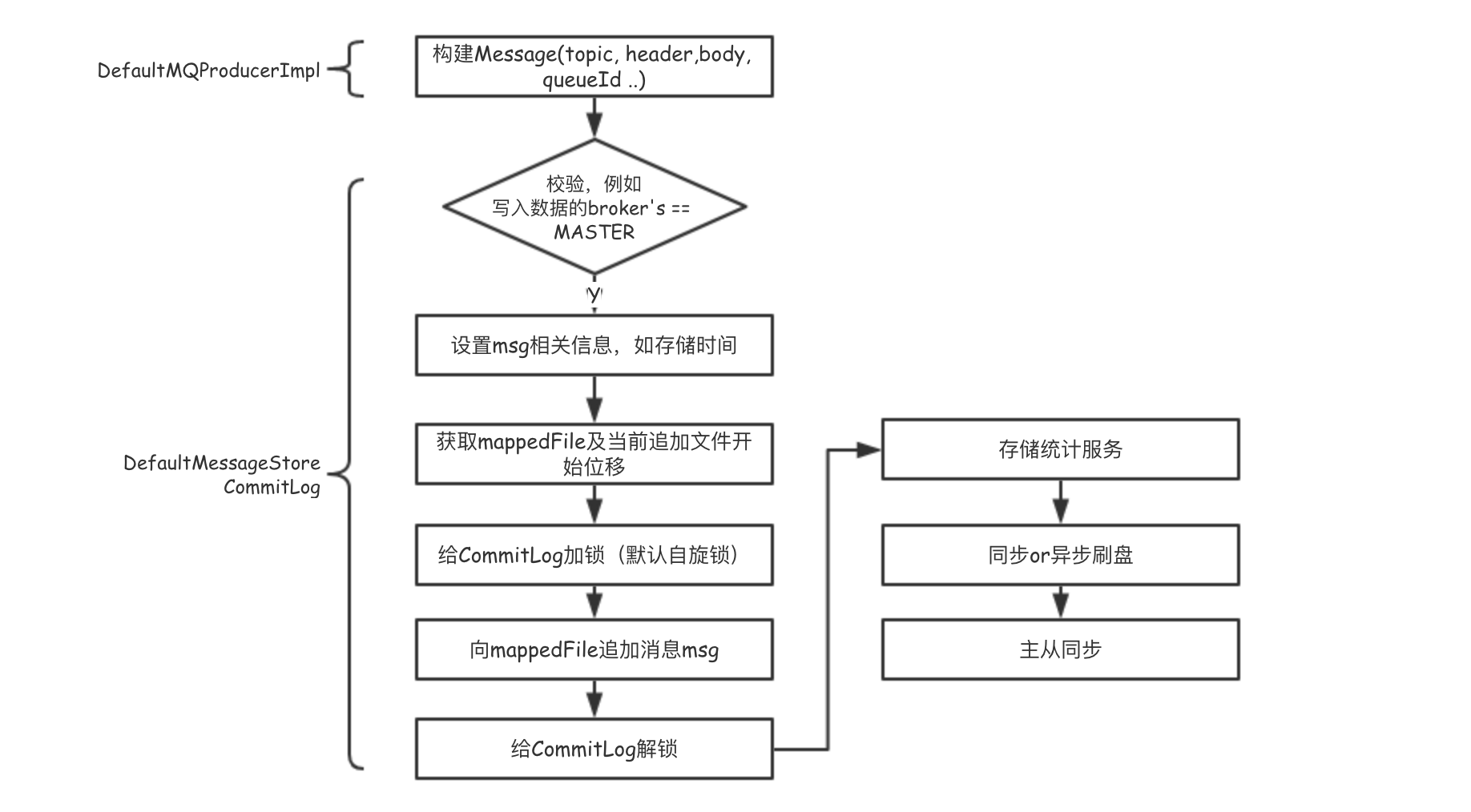
broker在接收到Producer发送的消息之后,会同步或者异步地刷盘。一般来说,数据存储为了追求高吞吐,会先将数据写入到内存,然后再刷盘到磁盘中进行持久化。1
private final FlushCommitLogService flushCommitLogService;
- 同步刷盘:当数据写到内存之后立刻刷盘,在保证刷盘成功的前提下响应client
- 异步刷盘:数据写入内存后,直接响应client, 异步将内存中的数据持久化到磁盘上。
Consumer消费消息
通过PullMessageProcessor处理消费消息。1
2
3public GetMessageResult getMessage(final String group, final String topic, final int queueId,
final long offset, final int maxMsgNums,
final SubscriptionData subscriptionData);
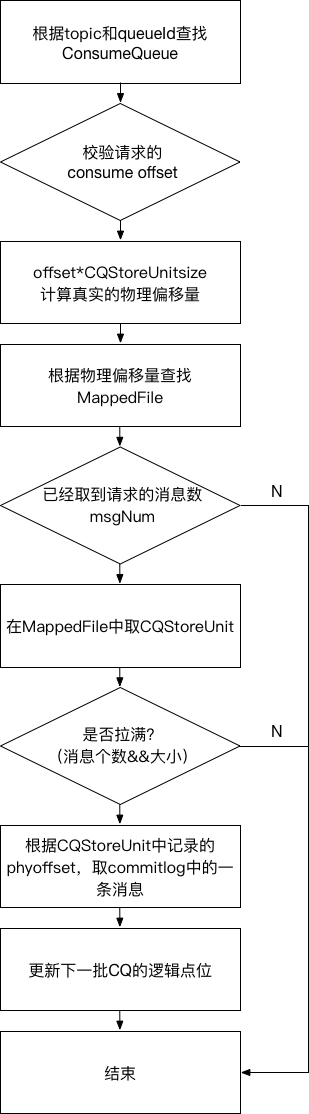
在根据topic和queueId在指定consumeQueue中第offset个消息开始,拉取maxMsgNums条消息时,首先根据offset找到consumeQueue中的目标MappedFile,然后计算offset在MappedFile中真实的物理偏移量,开始依次读取maxMsgNums条consumeQueue记录CQStoreUnit,回顾之前的数据存储图,CQStoreUnit中存储了此条消息在commitlog中的真实物理偏移和大小,以此为依据在commitlog的消息记录(过程与读取consumeQueue的CQStoreUnit相似,都是先找MappedFile,再取数据)。
为了防止一次性拉去的消息太多,阻塞其他任务,会从以拉取消息的个数和内存大小两个角度限制一次消息拉去的量。
索引
索引组件用于创建索引文件集合,RocketMQ允许我们在消息体的property字段中设置一些属性信息记为keys,当消费者想要获取某个topic下的某个key的消息时候能够快速响应。索引组件的具体实现是通过IndexFile来操作的,逻辑结构图如下:
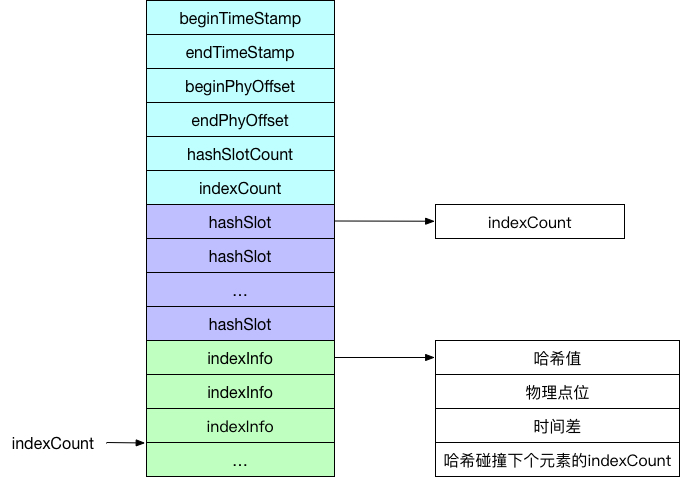
其实,IndexFile就是一个Hash表的具体实现。头字段(蓝色区域)用于记录当前IndexFile文件中内存的使用情况及最新修改的时间戳,哈希桶(紫色区域)用于记录索引信息的哈希值槽位,真实的索引信息(绿色区域)存储在最后,按照索引信息的录入顺序,依次存储。
当录入索引信息的时候,以topic#key为键,计算其哈希值,对哈希桶的总数取余,定位当前索引信息的哈希槽位。由于索引信息按序录入,所以当索引信息一到的时候,其存储位置就固定了,只需要在哈希槽位中记录其位置信息即可,即上图的indexCount。在发生哈希碰撞的时候,采用头插,以最新索引信息的indexCount覆盖哈希槽位的旧值,并把旧值记录在索引信息中。
当以某个topic和key取对应消息的物理点位时,首先定位槽位,然后遍历碰撞的“链表”,取到所需要的信息即可。
IndexFile文件内部的查找就是Hash查找的过程,那如何查找IndexFile呢?这就需要用到IndexFile头中的beginTimeStamp字段和endTimeStamp字段了,它们代表了当前索引信息中第一条和最后一条索引的更新时间。消费者查找时,出了topic和关键字信息,还需要指定时间段。索引组件根据请求的时间段,从后往前匹配。
总结系列文章:
- RocketMQ源码分析1--Remoting
- RocketMQ源码分析2--NameServer
- RocketMQ源码分析3--Store数据存储
- RocketMQ源码分析4--Broker模块
- RocketMQ源码分析5--Client之Consumer模块
- RocketMQ源码分析6--关于RocketMQ你想知道的Questions