历史
Kafka是LinkedIn开源的,主要特点Pull模式来处理消息消费,追求高吞吐。设计之初就是为了解决日志收集和传输,对可靠不做保证。适合大数据,IO高吞吐量的业务,例如做数据流计算的数据通道。对了它是Scala开发的。
RocketMQ是阿里开源的(是Java的),设计思路起源于Kafka。最初使用场景是为了支持淘宝双十一实时订单场景,因此更关注消息的可靠传输和事务。据说在阿里广泛用于交易、充值、也用在流计算,日志流式处理,binlog分发场景。
架构上
- Kafka的每台Broker机器,既是Master,也是Slave。因此Master/Slave 是逻辑概念。
- RoctetMQ Broker机器只能要么是Master,要么是Slave。因此Master/Slave 是物理概念,这个在初始的机器配置里面就固定了。
RocketMQ架构: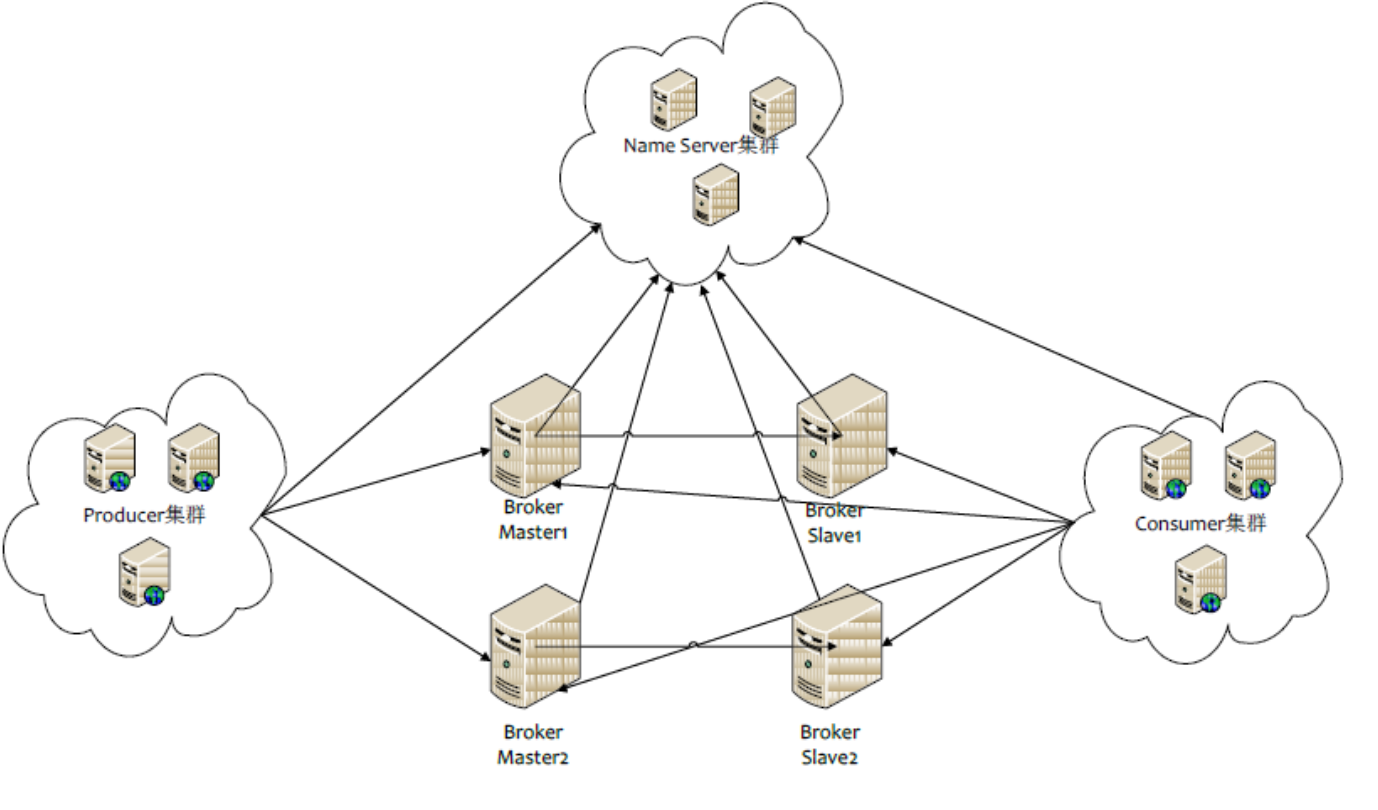
Kafka架构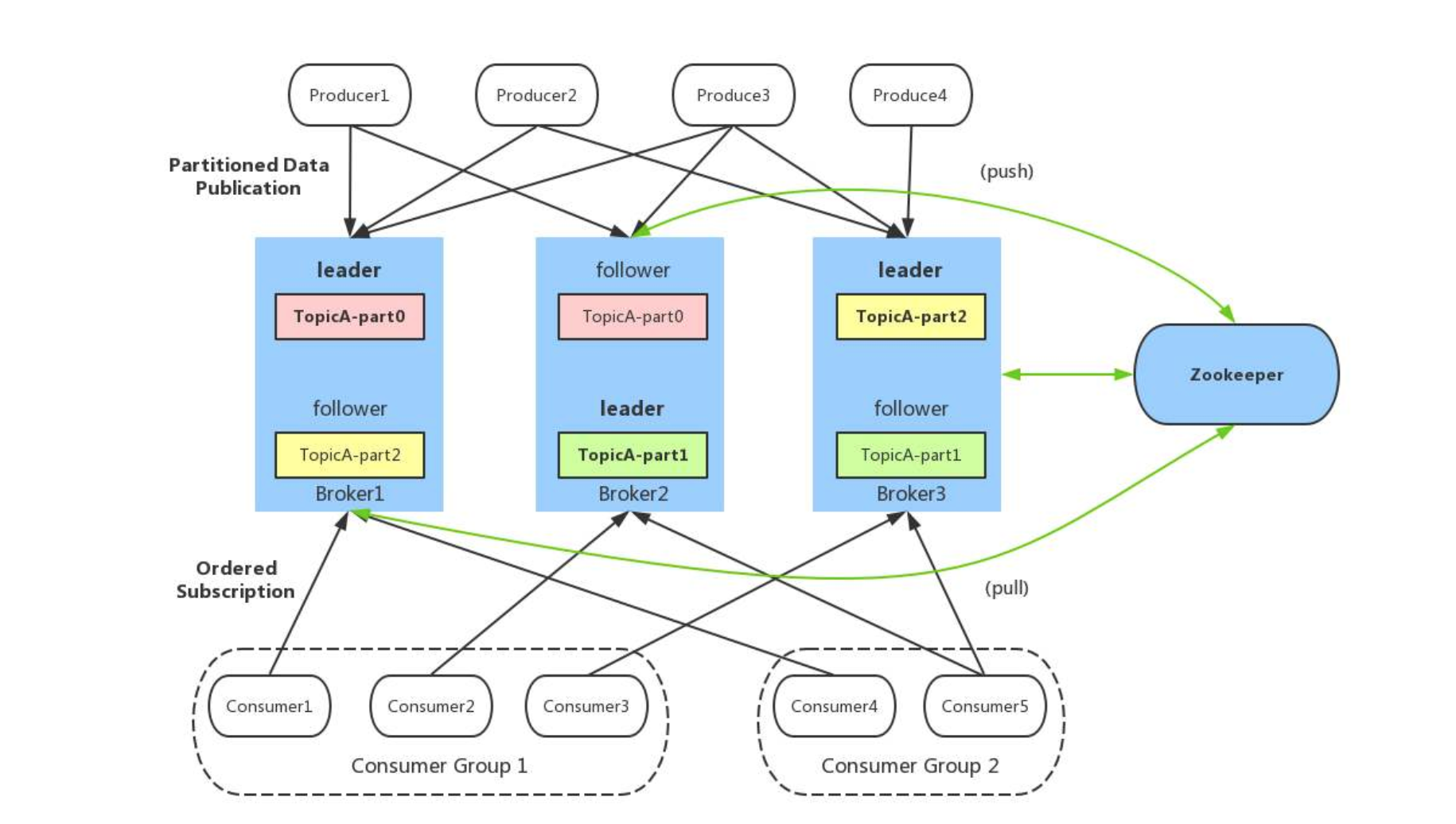
服务发现
Kafka使用了ZK做服务发现,选举Master/Slave,RocketMQ自己实现了的NameServer。
RocketMQ 之所以不用ZK,很大程度是因为它不需要选举Master/Slave,如上文所述RocketM的QMaster/Slave 是物理概念,这个在初始的机器配置里面就固定了。 因此RocketMQ自己写了一个简单的服务发现,没有使用相对较重的ZK。
可靠性
- RocketMQ支持异步实时刷盘,同步刷盘,同步Replication,异步Replication
- Kafka使用异步刷盘方式,异步Replication/同步Replication
RocketMQ的同步刷盘在单机可靠性上比Kafka更高,不会因为操作系统Crash,导致数据丢失。
Kafka同步Replication理论上性能低于RocketMQ的同步Replication,原因是Kafka的数据以分区为单位组织,意味着一个Kafka实例上会有几百个数据分区,RocketMQ一个实例上只有一个数据分区,RocketMQ可以充分利用IO Group Commit机制,批量传输数据,配置同步Replication与异步Replication相比,性能损耗约20%~30%,Kafka没有亲自测试过,但是个人认为理论上会低于RocketMQ。
消费失败重试
- Kafka消费失败不支持重试。
- RocketMQ消费失败支持定时重试,每次重试间隔时间顺延
总结:例如充值类应用,当前时刻调用运营商网关,充值失败,可能是对方压力过多,稍后再调用就会成功,如支付宝到银行扣款也是类似需求。
这里的重试需要可靠的重试,即失败重试的消息不因为Consumer宕机导致丢失。
事务
- Kafka不支持事务消息。
- RocketMQ 支持事务消息。
消息顺序
- Kafka支持消息顺序,但是一台Broker宕机后,就会产生消息乱序
- RocketMQ支持严格的消息顺序,在顺序消息场景下,一台Broker宕机后,发送消息会失败,但是不会乱序
Mysql Binlog分发需要严格的消息顺序
参考
总结系列文章:
- RocketMQ源码分析1--Remoting
- RocketMQ源码分析2--NameServer
- RocketMQ源码分析3--Store数据存储
- RocketMQ源码分析4--Broker模块
- RocketMQ源码分析5--Client之Consumer模块
- RocketMQ源码分析6--关于RocketMQ你想知道的Questions
- RocketMQ与Kafka的区别